





.jpg)
RPC Fast engineers were excited to post these benchmarks, as were our competitors and partners. And here’s the big day—we’ve published them, with a bit of practical extra. We share our experience, best practices, and professional answers to the “why” and “how” questions you might have.
TL;DR
- Detection: Aperture won first-look in 99.97% of 20,000 transactions vs Yellowstone, averaging −10.7 ms (−35.5 ms P95, −50.7 ms P99)—meaningful if you still run Yellowstone.
- Detection ceiling: Against a raw firehose, Shredstream is only ~0.1 ms faster on average (0.4 ms P95, 2.1 ms P99); Aperture trades that sliver for server-side filters and reduced bandwidth.
- Landing: In a 20-run set, Beam landed at 330 ms avg / 589 ms P90 vs 457 ms / 1,065 ms for standard RPC—standard RPC acks faster, but its tail is far worse.
- Modes matter: Beam offers fastest and mev_protect; choose per-transaction intent, not globally.
- Infra is the variance lever: Co-location can bring workload↔node latency under 0.2 ms; it reduces variance rather than adding a headline number.
Disclaimer + how to read these benchmarks
Every number below was produced on a specific rig—Frankfurt, Latitude.sh f4.metal.small, May 19, 2026, with linked runs. Your datacenter, peering, leader schedule luck, and client implementation will move these numbers. Treat them as directional, not as a guarantee for your topology. The methodology, scoring formulas, and run links are public on the docs benchmarking page—verify them yourself.
The only benchmark that matters is the one run inside your setup. Run Aperture/Beam against your current detection and submission paths, in your region, on your transaction shapes.
Two-leg model of Solana HFT performance
Solana HFT performance reduces to two legs. You can be elite at one and still lose money if the other is weak.
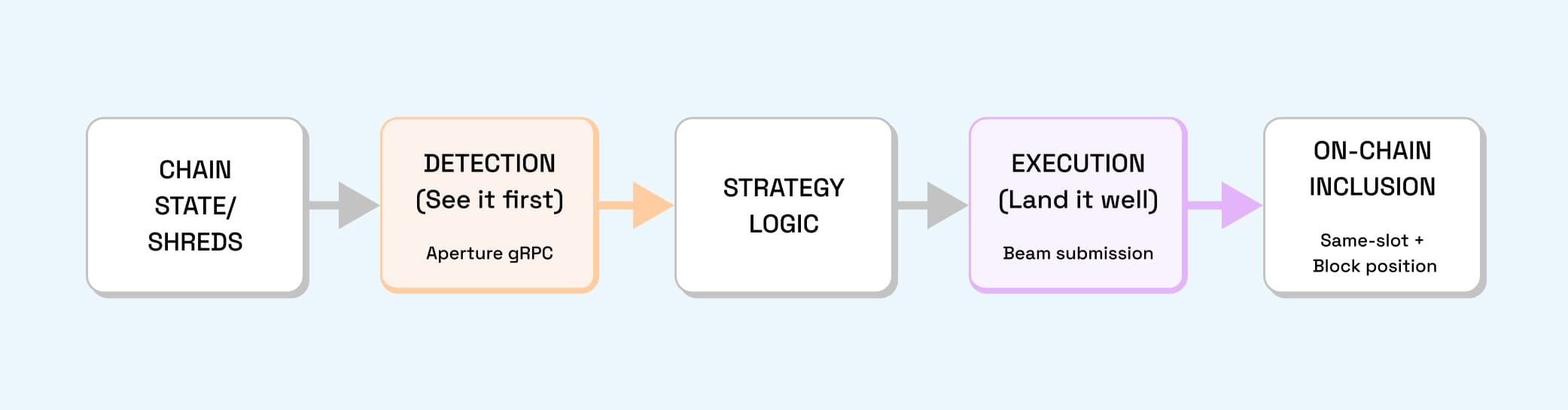
- Detection (See it first): How early you decode a relevant transaction or slot. Measured in arrival latency and first-look win rate.
- Execution (Land it well): Whether your transaction lands, in which slot, and at what index. Measured in landing latency, same-slot rate, and success ratio.
RPC Fast maps these legs to Aperture (detection) and Beam (execution), with dedicated nodes as the substrate that controls variance for both.
Detection / Streaming benchmarks—Aperture
See it first means which feed decoded a given transaction first. Tails (P95/P99) matter more than the average here: the slow 1–5% of events is exactly where you miss a fill or get beaten into a pool.
Numbers we have
Against Yellowstone over 20,000 transactions, Aperture was first in 99.97% of slots—19,994/20,000—with an average lead of 10.7 ms, 35.5 ms at P95, and 50.7 ms at P99.
This proves Aperture beats a Yellowstone-style RPC-node-derived feed, because Aperture decodes directly from validator shreds before full execution. It does not prove it beats every low-level feed (see Shredstream below), and it does not give you execution metadata—Aperture omits errors, balance changes, CPI, logs, compute units, and status by design.
The Yellowstone comparison is aimed at teams still on Yellowstone. Aperture is positioned as close to a drop-in replacement (Yellowstone-compatible subscription model and filter semantics), with nuances—notably ALTs resolved for v1 only and possibly incomplete, since there is no full replay.
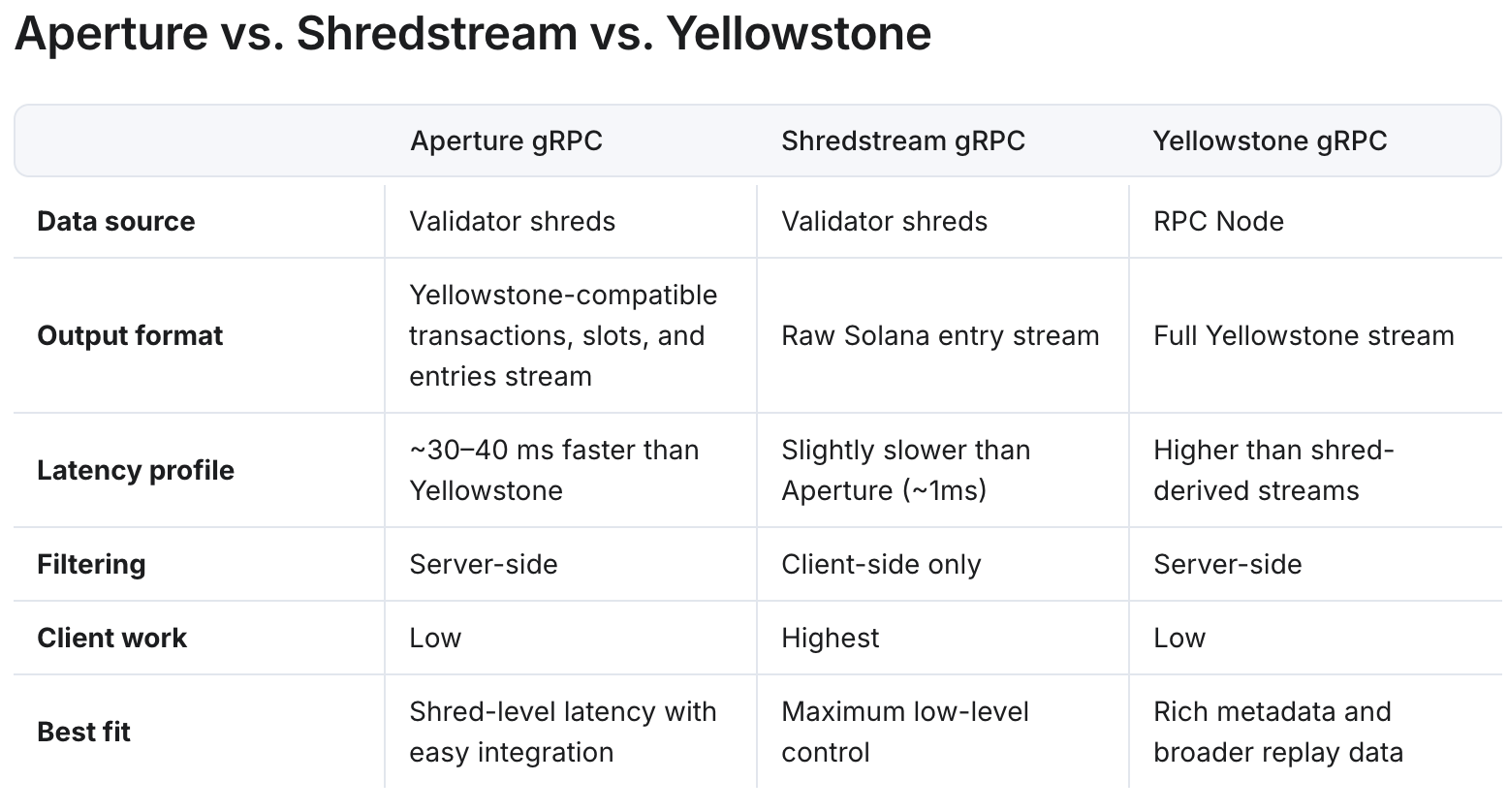
Aperture vs Shredstream context
Against a raw firehose, Shredstream is only ~0.1 ms faster on average, 0.4 ms at P95, and 2.1 ms at P99—and Aperture still took first-look in 4.41% of slots vs Shredstream’s 95.59%.
Don’t hide the tradeoff: Shredstream is marginally faster. The point is what you pay for that margin. Aperture does server-side filtering and reduces bandwidth, while Shredstream pushes a full client-side-decoded stream.
For many teams, the sub-millisecond delta is irrelevant next to the engineering cost. Server-side filters (is_vote, plusaccount_include/account_exclude/account_required) reduce client implementation time and bandwidth usage.
Filtered vs Raw streams—Who should choose which?
| Dimension | Aperture (filtered, shred-native) | Shredstream (raw firehose) | Yellowstone (RPC-derived) |
|---|---|---|---|
| Latency | Shred-level: ~30–40 ms faster than Yellowstone | Marginally fastest (~1 ms over Aperture) | Slowest of the three |
| Filtering | Server-side | Client-side only | Server-side |
| Client work | Low | Highest | Low |
| Metadata depth | Minimal (pre-execution) | Minimal (raw) | Full replay metadata |
| Best fit | Shred speed + easy integration | Max low-level control | Correctness / rich metadata |
Execution / Landing benchmarks—Beam
Beam scores providers on five normalized metrics: landing latency (ms), landing latency (slots), index-in-block, same-slot rate, and success ratio. For latency metrics, P90 is weighted 4× the average—because tail latency is where landing fails under load. The final score is the unweighted average of all five.
Beam vs standard RPC
Over 20 runs, Beam (astralane) landed at 330 ms avg / 589 ms P90 at a 97.42% performance score, vs standard RPC at 457 ms / 1,065 ms and 82.20%. Standard RPC acks faster (28 ms vs 53 ms) because there’s no routing overhead, but its landing latency is 38% higher.
Beam vs standard RPC — landing latency
Yes, that’s not apples-to-apples. Beam is routed, aggregated, score-driven delivery across multiple provider paths; standard RPC is a single endpoint. In product terms, it still matters: the comparison shows what routed delivery buys you—lower landing latency and a dramatically tighter tail—at the cost of a slower ack.
Beam exists to position for same-slot landing, higher block position, and MEV protection, not to win an ack race. And it is not cheaper—you pay for speed/MEV protection. Context, not a measured claim.
| Provider | Avg landed | P90 landed | Performance score | Avg ack |
|---|---|---|---|---|
| beam-astralane | 330ms | 589ms | 97.42% | 53ms |
| rpcfast-rpc (standard) | 457ms | 1,065ms | 82.20% | 28ms |
Beam modes: fastest vs mev_protect
Beam routes through SWQoS-backed validators, Jito Block Engine, and other provider paths, and exposes two modes (default fastest):
| Mode | Goal | Expected tradeoff | When to use |
|---|---|---|---|
fastest |
Lowest submission latency | No protection against toxic MEV | HFT, arb, liquidations, same-slot races |
mev_protect |
Protect from frontrun, backrun, and sandwich | Prioritizes privacy over raw speed | Sensitive order flow, execution privacy |
Per the Beam docs: every send must include a valid tip instruction (rotate the tip account), Beam ignores maxRetries/preflight on the send path (handle retries app-side), and mev_protect/sendBundle are supported only by astralane and bloxroute. Best practice: submit to multiple providers in parallel.
Dedicated nodes/clusters: Where infra fits
Aperture and Beam set the ceiling; dedicated infra determines how consistently you reach it. Infra changes variance, topology control, isolation, and peering/colo—not a single headline metric.
.jpg)
What the data shows on the substrate layer:
- Shredstream improves processed-transaction arrival by up to 270 ms on a Yellowstone geyser subscription,
- A node with Jito receives 99.71% of transactions faster, averaging a 120 ms advantage (270 ms at P99).
- On the path side, disabling CloudFlare and co-locating in the same DC can bring workload↔node latency under 0.2 ms.
The broader infra framing—including Jito/bloXroute submission paths—is covered in the low-latency HFT playbook.
3-stage maturity ladder
.jpg)
The maturity ladder is just a way of saying that the KPI you optimize changes as you climb, and so does the stack.
- Stage 1 (Working) is about landing reliably.
The metric that matters is success ratio with timely detection—nothing fancier. The stack is a drop-in Aperture gRPC stream plus Beam in fastest mode. Minimal moving parts, quick to stand up, and enough to stop bleeding on dropped transactions.
- Stage 2 (Competitive) moves the question from "did it land" to "how consistently, and how fast."
You start measuring and cutting P90/P99 tail latency—the same tail emphasis RPC Fast's Beam scoring bakes in by weighting P90 4× over average. The stack grows: server-side filters, multi-provider submission, and a dedicated node so you stop competing on shared, noisy infrastructure.
- Stage 3 (Elite execution) is where the KPI becomes same-slot inclusion and block position, not mere inclusion.
At this level, the gap between winning and losing is placement inside the slot. The stack combines Aperture for first-look detection, Beam for tuned landing (mev_protect where the order flow demands it), and a colocated dedicated node or HA cluster to compress the detect-to-submit hop toward the sub-0.2 ms range.
The climb is a trade—you give up simplicity for control (more filtering, more routing, more infra ownership), and the wins stack only if the earlier legs are already solid.
The throughline holds at every stage: these numbers describe RPC Fast's test conditions, not yours. Re-benchmark in your own topology before you trust any of them—headline figures are a starting point, not a guarantee.
Bot-type mapping
Detection KPIs reference first-look/percentile definitions; execution KPIs reference Beam scoring metrics.
| Bot type | Latency budget | Detection KPIs | Execution KPIs | Recommended stack |
|---|---|---|---|---|
| MEV searchers | Tightest (sub-slot) | First-look win rate; P99 detection | Same-slot rate; index-in-block |
Aperture (filters) + Beam
(mev_protect for sensitive flow,
fastest for races)
|
| Arbitrage | Very tight | First-look on target pools | P90 landing; success ratio |
Aperture + Beam
fastest, multi-provider
|
| Keepers / liquidations | Tight, event-driven | Detection reliability on trigger accounts | Success ratio; same-slot |
Aperture filters + Beam
fastest + dedicated node
|
| Market making | Moderate, continuous | Stable low-latency state; bandwidth efficiency | P90 landing; quote-cancel reliability |
Aperture (reduced bandwidth) + Beam;
colo for variance
|
| AI-driven ms execution | Tight, bursty | Low-jitter feed; tail-bounded detection | P90/P99 landing; same-slot consistency |
Aperture + Beam (mode per inference) +
colo cluster
|
Validate in your own topology
The published runs are honest and linked, but they describe a single rig on a single day. Your edge depends on your region, peering, client code, and the specific accounts you watch.
.jpg)
Before you re-architect, measure:
- Run Aperture against your current Yellowstone/Shredstream detection path on your accounts.
- Run Beam (
fastestandmev_protect) against your current submission path, tracking P90 landing, same-slot rate, and index-in-block. - Re-test after co-location to quantify variance reduction.
Ask RPC Fast engineers in the chat how to benchmark Aperture and Beam inside your setup and topology—compare against your live numbers, then decide whether to pay for detection, landing, or infra first.
.jpg)



.jpg)

