





Your AI trading agent is only as fast as the data it sees. On Solana, where a slot closes every 400 milliseconds, a 200ms polling delay does not just slow you down—it puts you two slots behind the market. By the time your agent reacts, the opportunity is gone, and someone else's bot already landed the trade.
This is the infrastructure problem that separates profitable AI agents from expensive experiments.
The Problem With Polling and Standard APIs
Most teams start with JSON-RPC polling. It is the path of least resistance: call getAccountInfo, parse the response, repeat. It works for dashboards and analytics. It does not work for execution-critical AI agents.
Standard Solana RPC endpoints are request-response by design. Your agent asks, the node answers. Between those two moments, the chain has moved. Under load, public endpoints throttle, queue, and drop requests. Your agent's signal arrives stale.
The deeper issue is architectural. Polling creates a feedback loop with a fixed floor: you are always reacting to history, never to the present. For an AI agent making decisions on DEX price movements, wallet activity, or MEV signals, that floor is the ceiling on your alpha.
The fix is not faster polling. It is eliminating polling entirely.
What data AI trading agents need on Solana
AI trading agents on Solana consume several distinct data types, each with different latency requirements and processing characteristics:
- Account updates—DEX pool state, wallet balances, token accounts. Required for position sizing and risk checks.
- Transaction streams—raw or decoded, filtered by program or wallet. The primary signal source for copy-trading, MEV, and arbitrage agents.
- Slot and block events—leader schedule, slot confirmation, block finality. Required for timing transaction submission.
- Mempool-equivalent signals—on Solana, this means shred-level data: transactions decoded from validator shreds before full block processing.
- Price feeds and logs—program logs from DEX programs, swap events, and oracle updates.
How AI agents process streaming blockchain data
A well-designed AI agent separates ingestion from inference. The ingestion layer receives raw events from the stream, normalizes them, and writes to an in-memory state model. The inference layer reads that state, runs the model, and emits a decision. The execution layer signs and broadcasts the transaction.
Each layer has a latency budget. On Solana, the total budget from signal detection to transaction landing is roughly one slot—400ms. In practice, the best-performing systems achieve 200–300ms average end-to-end, with sub-50ms on the ingestion path alone.
How real-time Solana data streaming works
Solana's architecture is built around shreds. Instead of broadcasting full blocks, validators break blocks into smaller fragments called shreds and propagate them across the network. A shred contains unordered transaction data, a slot number, and its index within the slot.
This matters because shreds arrive before the block is finalized. An agent subscribed at the shred level sees transactions as they enter the validator pipeline—not after replay, not after confirmation. That is the earliest possible signal on Solana.
The standard path for streaming is Geyser, a plugin interface that lets RPC nodes emit account and transaction updates over gRPC. Yellowstone gRPC is the most widely used Geyser implementation. It gives you a structured, filterable stream of transactions, accounts, slots, blocks, and logs—with significantly lower latency than WebSocket subscriptions.
Common bottlenecks in Solana data streaming
Even with gRPC, teams hit walls. The most common failure modes:
- RPC node replay lag—Yellowstone emits data after the node has processed and validated shreds. That adds 30–100ms depending on node load.
- Shared infrastructure throttling—public or oversold shared nodes degrade under load. Your stream competes with hundreds of other subscribers.
- Client-side decoding overhead—raw shred streams require your application to decode and reconstruct entries. Without purpose-built tooling, this adds latency and engineering complexity.
- Connection instability—long-lived gRPC streams drop on idle connections without proper TCP and HTTP/2 keepalive configuration.
- Geographic distance—a Frankfurt validator and a US-hosted agent add 80–120ms of round-trip latency before your code runs a single line.
Infrastructure requirements for high-speed data processing
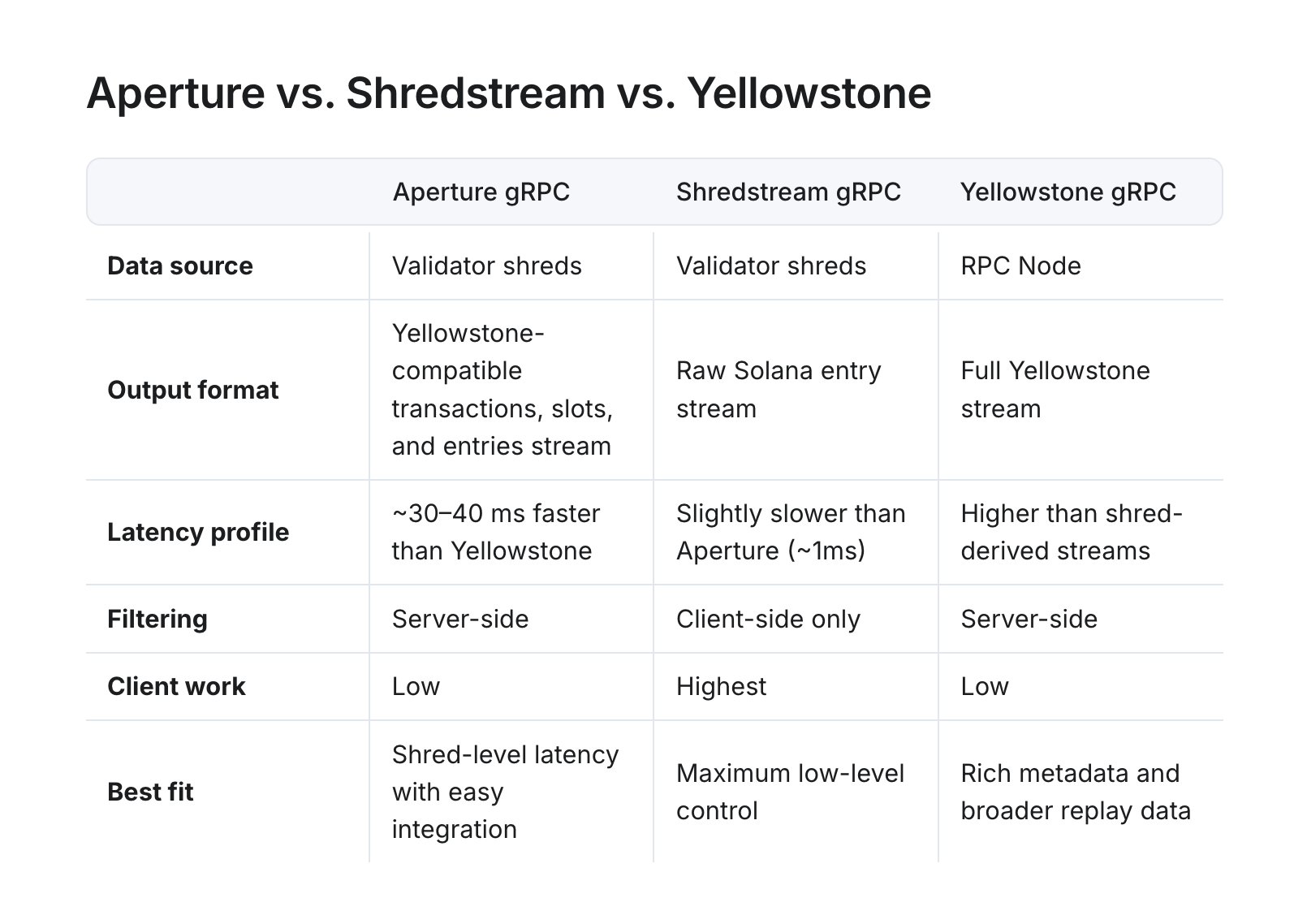
WebSockets vs Yellowstone gRPC vs Shredstream
Choosing the right streaming interface is the first infrastructure decision. Each option trades latency, metadata richness, and implementation complexity differently.
| Interface | Data source | Latency profile | Filtering | Client work | Best fit |
|---|---|---|---|---|---|
| WebSocket (pubsub) | RPC node | Highest | Limited | Low | Dashboards, light monitoring |
| Yellowstone gRPC | RPC node (Geyser) | Medium | Server-side | Low | Rich metadata, post-execution data |
| Aperture gRPC | Validator shreds | ~30–40ms faster than Yellowstone | Server-side | Low | Earliest visibility, Yellowstone-compatible |
| Shredstream gRPC | Validator shreds | ~50–100ms faster than Yellowstone | Client-side only | Highest | Maximum control, low-level decoding |
WebSockets are the slowest option for trading workloads. They are appropriate for read-heavy applications that do not compete on execution speed.
Yellowstone gRPC is the right default for most AI agents. It delivers structured, filterable streams of transactions, accounts, and blocks with low implementation overhead. The tradeoff is that data arrives after full node replay—meaning you see execution metadata (inner instructions, balance changes, logs) but at higher latency than shred-derived streams.
Shredstream gRPC bypasses node replay entirely. You subscribe directly to the shred feed and receive transactions 50–100ms earlier on average than Yellowstone. The cost is client-side decoding: your application must reconstruct Solana entries from raw shreds. RPC Fast provides a working Rust reference implementation to reduce that burden.
Aperture gRPC is RPC Fast's purpose-built solution that combines shred-level speed with Yellowstone-compatible ergonomics. It reconstructs validator shreds into a structured gRPC stream, delivers transactions 30–40ms faster than standard Yellowstone, and supports server-side filtering—so you do not pay bandwidth for events your agent does not need. It is the right choice when you want shred-level latency without building a shred-decoding pipeline from scratch.
Building a low-latency data pipeline
Here is the architecture that production AI trading agents on Solana run. Every layer has a specific job. Nothing is shared between the latency-critical path and background workloads.

The key design principle is that the ingestion layer and the AI inference engine run on a VPS co-located with the RPC Fast node in the same data center. Network hops between data ingestion and decision-making are measured in microseconds, not milliseconds.
For the ingestion layer, here is a minimal Rust subscription to Aperture gRPC filtering Pump.fun transactions—the same interface used in production copy-trading systems:
For Yellowstone gRPC (full metadata, post-execution), the subscription pattern is identical—swap the endpoint for your Yellowstone URL. Reference implementations in Go, Rust, and TypeScript are available here.
For Shredstream, use the deshred.rs reference here as your starting point. It handles shred reconstruction into human-readable Solana entries.
RPC Fast Data Streaming solution for Solana AI agents
RPC Fast is built on bare-metal infrastructure in Frankfurt, tuned at the kernel and NIC level for trading workloads. The platform delivers three streaming interfaces—Yellowstone gRPC, Shredstream gRPC, and Aperture gRPC—alongside standard JSON-RPC, all from the same node.
Here are some bench numbers: <20ms end-to-end actionable latency, <0.02ms gRPC stream event latency when subscribing from the nearest location, and 99.9% consistent data propagation. The platform is connected to DoubleZero, a high-throughput, dedicated internet layer built for Solana that reduces tail latency and improves execution consistency under heavy network load.
A Rust-based copy-trading bot built on RPC Fast infrastructure demonstrates what this means in practice. The bot subscribed to Shredstream and Yellowstone gRPC to intercept target wallet activity before full block processing. Co-located in Frankfurt alongside the RPC Fast node, it achieved:
- Transaction landing averaged 200–300ms end-to-end.
- Lowest recorded landing: 15ms.
- Execution accuracy: same slot or +1 slot behind the target wallet.
- Sub-1ms RPC response times across a 100,000-call stress test.
Node uptime over three months: only 2–3 short outages of a few seconds each.
The client’s own words: “I consistently secured the same slot and, in most cases, landed +1 right behind the target wallet.”
Read the full case study
RPC Fast SaaS plans give teams access to these streaming capabilities without deploying dedicated infrastructure, starting at $0 on the Start plan. The Stream plan ($249/month) includes Yellowstone gRPC with up to 10 concurrent streams, 60M monthly credits, and 150 req/s. The Aperture plan ($499/month) adds Shredstream gRPC (up to 10 streams), Aperture gRPC, 25 Yellowstone streams, and priority support with an 8-hour SLA.
For teams that have outgrown shared infrastructure, dedicated Solana nodes include all three streaming interfaces at no additional cost, with no rate limits, custom plugins, and hands-on support from Solana-native engineers.

Unlock peak trading performance with our Solana HFT solution
-
Up to 5x faster than shared RPCs
-
83% first-block inclusion rate
-
Real-time market data via ShredStream
-
Curated plugin pack: Jupiter, Raydium, Geyser & more
Best practices for Solana AI agent data infrastructure
These are the patterns that separate stable production systems from bots that work in testing and break under load.
Co-locate aggressively. Deploy your agent in the same data center as your RPC node. Frankfurt is the primary Solana network hub in Europe. Recommended providers for co-location: OVH (in partnership with Dysnix/RPC Fast), Teraswitch, Cherry Servers, Latitude. The difference between same-DC and cross-region latency is 80–120ms—more than a full slot.

Separate streaming from state reads. Use gRPC streams for event detection. Use JSON-RPC (getAccountInfo, getMultipleAccounts) for state validation before transaction submission. Mixing them on the same path creates contention.
Keep connections warm. Cold gRPC connections add 10–50ms on first use. Maintain persistent connections with HTTP/2 keepalive and TCP keepalive configured. For Aperture gRPC, the recommended settings are http2_keep_alive_interval: 30s and keep_alive_timeout: 10s.
Use parallel transaction landing. A single sender is a single point of failure. Run Helius, bloXroute, and a fallback path in parallel. The first confirmed landing wins. Monitor all paths via getSignatureStatuses for diagnostics.
Reserve your trading node for the hot path. Historical queries, backtesting, and analytics workloads belong on separate endpoints. Mixing them with live trading streams degrades latency under load.
Match the stream to the use case. Not every AI agent needs shred-level data. The table below maps agent types to the right streaming interface:
| Agent type | Recommended stream | Why |
|---|---|---|
| Copy-trading bot | Shredstream or Aperture gRPC | Earliest wallet activity detection |
| MEV / arbitrage searcher | Aperture gRPC | Shred speed + server-side filtering |
| DEX liquidity monitor | Yellowstone gRPC | Account updates + balance changes |
| On-chain analytics agent | Yellowstone gRPC | Full metadata, logs, inner instructions |
| Slot-timing agent | Yellowstone gRPC (slots) | Leader schedule, slot confirmation |
| Risk management layer | JSON-RPC + Yellowstone | State reads + event triggers |
Monitor at the infrastructure layer, not just the application layer. Track RPC response times, stream event gaps, and slot lag separately from your agent's PnL metrics. When a strategy underperforms, you need to distinguish infra problems from model problems. Grafana dashboards with node health metrics are standard practice on RPC Fast dedicated deployments.
An invitation to the better infrastructure
Your AI trading agent's edge starts at the data layer. The model, the strategy, the execution logic—none of it matters if the signal arrives late. Get the infrastructure right first.
See what sub-20ms Solana data streaming looks like for your specific workload
Try RPC SaaS for free.jpg)





