





.jpg)
Solana processes 65,000+ TPS. Pump.fun launches hit 200+ competing bots in the first 500 milliseconds. Only 10–15% of sniper bots achieve consistent landing rates. The bottleneck isn't your logic—it's your stack.
This piece is about the four infrastructure layers that decide whether a sniper bot lands or watches the slot go by. Each layer compounds with the others. Skip one and the rest don't help. The teams writing about sniper bots almost universally cover the first two—RPC and priority fees—and stop. That's why most sniper bot guides produce bots that lose money.
We're going to cover all four.
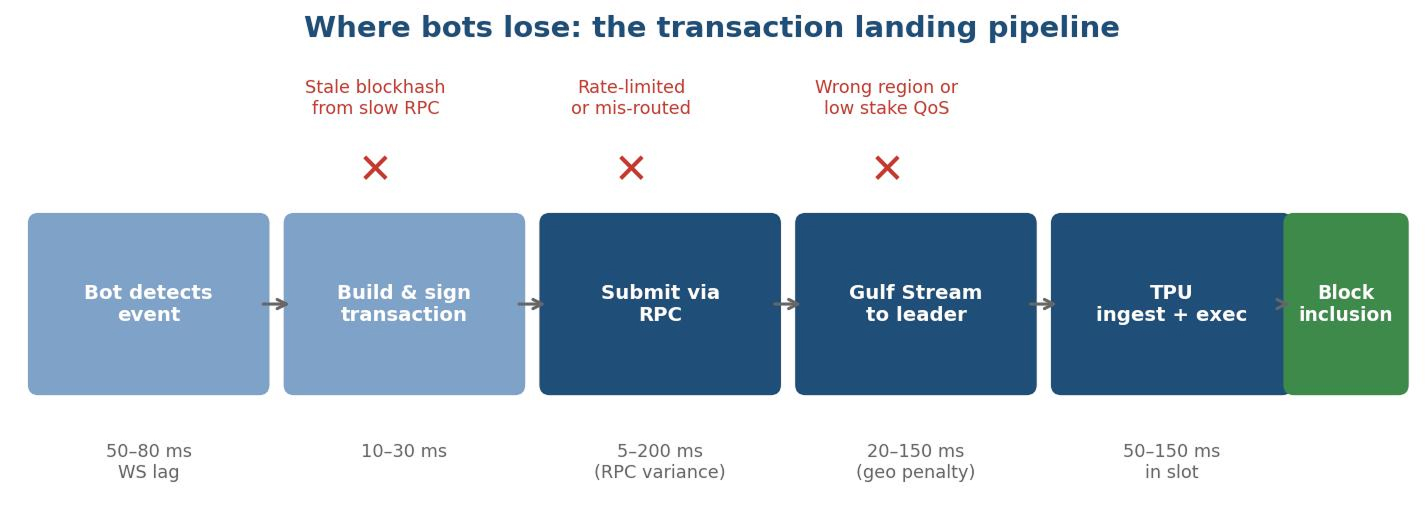
What "landing" actually means
Landing means the transaction reaches the leader's TPU, gets included in the block being assembled, and ends up in the canonical chain. That is one event. Everything before it—detection, decision, build, sign, submit—is preparation. Everything after it—confirmation, settlement—is post-hoc reporting. The bot's whole job is to win the race to the leader.
Walk the path a transaction takes:
- Detection. Your bot sees the event. For a Pump.fun migration sniper, that's an account write on the bonding curve.
- Build and sign. Construct the transaction, fill in the dynamic fields (mint, amount, slippage), sign with the pre-loaded keypair.
- Submit. Send the transaction to your RPC, which forwards it to the current leader via Gulf Stream.
- Ingest at TPU. The leader's Transaction Processing Unit pulls your transaction in, sigverifies it, and queues it for execution.
- Inclusion. Banking stage runs your transaction; if it succeeds, your buy is in the slot.
There are exactly three places bots reliably lose this race: between detection and submission (slow data feed), between submission and TPU ingest (bad RPC or wrong region), and inside the TPU under load (insufficient stake-weighted priority). Each one is a layer of the stack.

Layer 1—Your RPC endpoint is the starting gun
If your RPC takes 200ms to respond to getLatestBlockhash during a launch, you've already lost. The bot's reaction speed is bounded by its RPC's reaction speed. Public and shared endpoints hit rate limits and queue under load exactly when high-value launches happen—which means your bot operates on degraded infrastructure precisely when it matters most.
The target for competitive sniping is sub-20 ms RPC response on hot methods—getLatestBlockhash, getAccountInfo, sendTransaction, simulateTransaction. Anything above that is a structural disadvantage relative to bots running on dedicated infrastructure.
A simple benchmark script you can run against any RPC endpoint to check where you actually stand:
What good looks like on this benchmark: p50 under 15 ms, p95 under 30 ms, p99 under 60 ms. What "bad" looks like: p50 above 100 ms, p95 above 300 ms, p99 effectively unbounded during congestion. The provider's marketing page won't tell you which one they are. The benchmark will.
Layer 2—Why priority fees stop working
During Pump.fun launches and other contested slots, priority fees alone are not enough. A standard sendTransaction with a high priority fee competes for blockspace alongside every other transaction touching the same accounts—and during a viral launch, that's hundreds of bots. The fee race becomes an auction where you either win the highest position or land late.
This is what Jito bundles fundamentally fix: atomic, ordered execution at a specific slot position, paid for with a tip routed to the validator. In contested launches, validators effectively ignore unbundled high-fee transactions because bundle income outpaces priority-fee income—Jito tips alone account for more than 60% of all priority-fee volume on Solana in 2026.
The target for competitive Pump.fun sniping is >90% bundle acceptance rate across multiple regions. The path to that target:
- Submit through Jito Block Engine, not standard sendTransaction, for any launch-style strategy.
- Multi-relay parallel submission across Jito's NY, Frankfurt, Tokyo, and Amsterdam endpoints simultaneously, plus Astralane and QuickNode Lil-JIT as alternates.
- Dynamic tip calibration based on the last 50 blocks of accepted tip levels, scaled by the velocity of the bonding curve approaching completion.
- Pre-signed tip transaction included in the bundle's last position, with the SOL transfer to one of Jito's 8 tip accounts hardcoded for the hot path.
Competitive sniper teams routinely surrender 50–70% of expected profit to Jito tips during contested launches. That's the price of winning the slot. Hardcoded tips set during quiet hours are universally insufficient when the launch goes viral.
Layer 3—Geographic latency compounds everything
Physical distance from the slot leader is a constant tax on every layer above. A 100 ms cross-region penalty applies to your blockhash fetch, to your RPC submission, to your Jito bundle delivery. None of those latencies cancel. They stack.
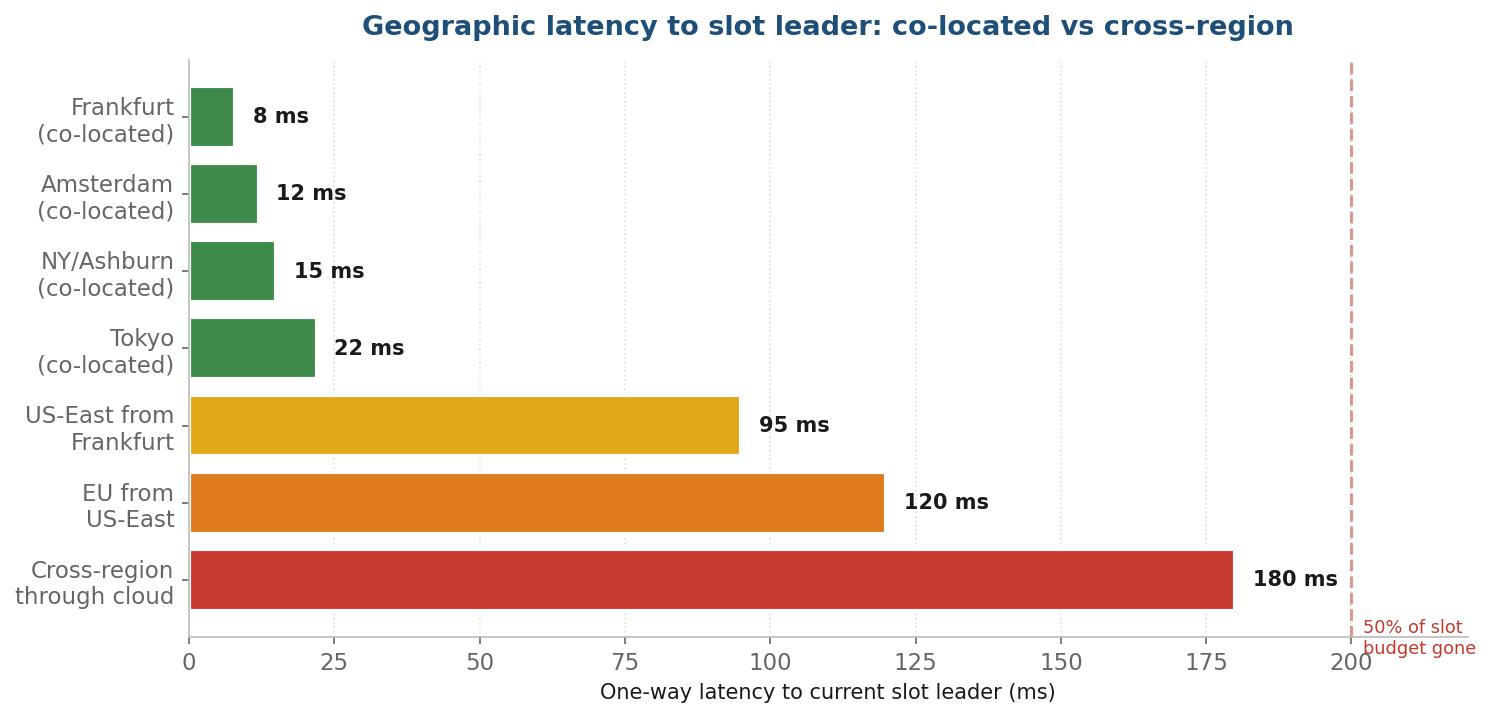
Solana's validator set concentrates in three regions: US East (Ashburn / NY), EU (Frankfurt / Amsterdam), and APAC (Tokyo / Seoul). A bot located in any one of these regions can reach a local leader in 5–20 ms. The same bot trying to reach a leader in a different continent operates with an 80–150 ms baseline before any code runs. On a 400 ms slot, that 80 ms geographic penalty alone consumes two slots of effective budget—your bot detects the event in the current slot, your transaction reaches the leader in the next slot, the leader you reached has already rotated out.
The fix is co-location with multiple regions, not single-region deployment. The minimum viable geographic setup:
- Frankfurt or Amsterdam for EU slot leaders, which control approximately half of network stake.
- Ashburn or NY for US East slot leaders.
- Tokyo for APAC slot leaders—lower stake share, but still meaningful.
- Automated failover under 50 ms between regions, so the bot uses whichever endpoint is closest to the current leader.
The wrong approach is a single cloud region and hoping the leader is nearby. That works when you're not competing. When you are, it's the single biggest reason your bot loses to bots that look otherwise equivalent.
Layer 4—You're firing on a notification that's already late
WebSocket subscriptions have a median notification latency of 50–80 ms—by the time your bot reacts, the slot has moved. This is the most overlooked of the four layers, partly because every tutorial uses WebSockets and partly because the latency is invisible until you measure it.
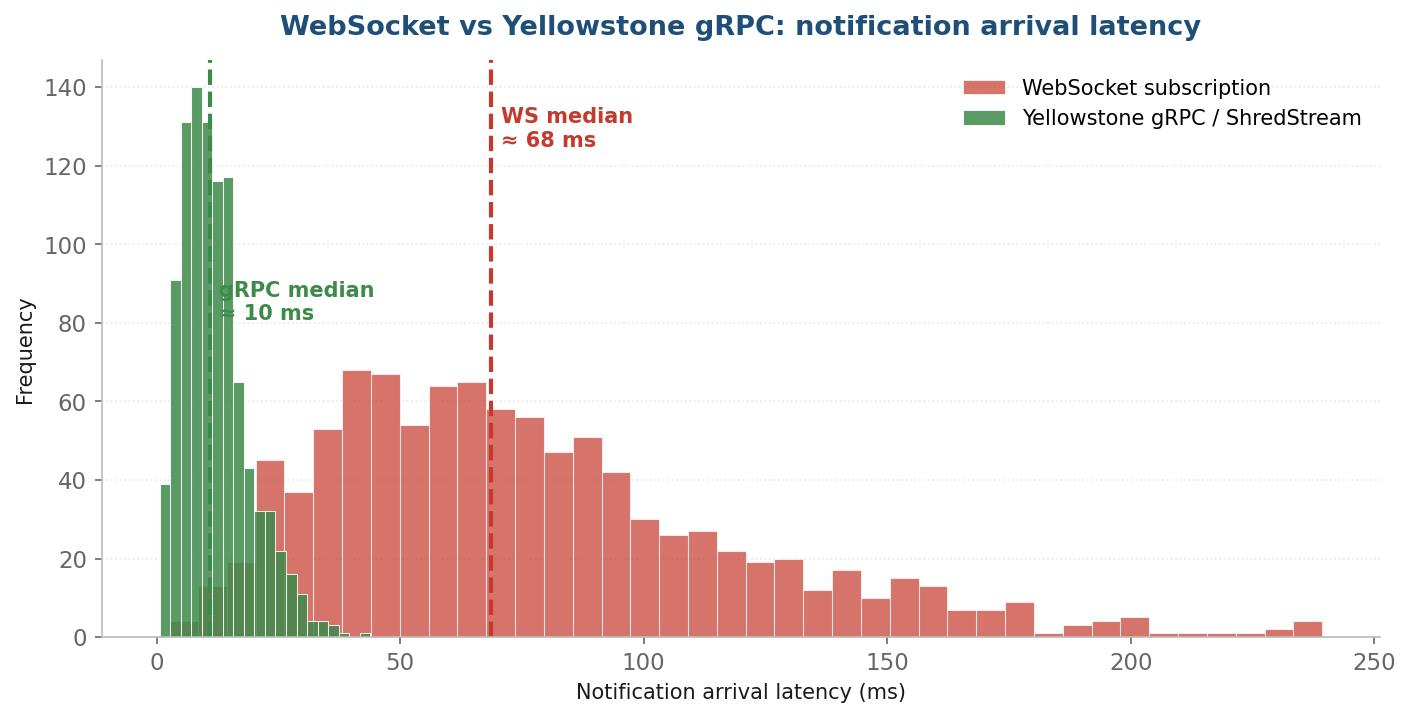
Yellowstone gRPC and Jito ShredStream are the data layers production sniper infrastructure runs on. They deliver events with median notification latency of 5–15 ms, an order of magnitude better than WebSocket. ShredStream specifically streams shreds—block fragments—from Jito-connected validators before Turbine fanout completes, giving an additional 50–200 ms of forward visibility on chain state.
A minimal Yellowstone gRPC subscription to a specific account looks like this:
Two things to note about this pattern. First, you subscribe to the specific account you care about, not to the program—server-side filters keep your event loop from drowning. Second, the commitment is processed, not confirmed, because you want the freshest possible state and Solana's atomic reverts make this safe for trading.
A counter-intuitive insight that most sniper bot guides miss: most bots watch the wrong event. For Pump.fun migrations specifically, the migration instruction lands a slot too late—the curve has already completed and the first bots have already fired. The right event to subscribe to is the second-to-last bonding curve buy that pushes deposits to ~84.5 SOL—the slot before the migration trigger. From there, the migration is mathematically inevitable, and you can pre-fire the buy transaction.
RPC Fast for sniper bot infrastructure
Most published sniper bot guides cover Layer 2 (priority fees) and parts of Layer 1 (use "a good RPC"). They leave Layer 3 (geographic positioning) and Layer 4 (notification stream) for you to figure out.
That's the gap RPC Fast fills directly. Dedicated bare-metal Solana nodes, co-located with validators across Frankfurt, Amsterdam, Ashburn, and Tokyo. Yellowstone Geyser gRPC and Jito ShredStream enabled by default. SWQoS-enabled transaction submission via staked validator identity. RPC Fast Beam for low-latency transaction delivery. Sub-50 ms automated failover between regions. Native multi-relay submission across Jito, Astralane, and Lil-JIT in parallel.
This isn't a sales section—it's the natural answer to Layer 1 and Layer 4. If your sniper is built on shared RPC and WebSocket subscriptions, the upgrade path to competitive landing rates is exactly this stack. The team has tuned 100+ trading bots, snipers, and AI agents in production on Solana, including production Pump.fun migration setups.
Free trial available—benchmark against your current setup and see the difference on p99 latency and bundle landing rate before you commit.
Measuring your bot's actual landing rate
If you can't measure your landing rate, slot lag, and RPC response time live, you can't tune any of the four layers. Most teams discover their infrastructure problems only after the P&L breaks. The metrics that matter, with targets versus typical shared-node values:
| Metric | Target | Typical shared-node value | Why it matters |
|---|---|---|---|
| Bundle landing rate | >90% | 30–60% | Direct measure of competitive position; the only metric that maps 1:1 to P&L |
| Slot lag (node vs chain tip) | 0–1 slot | 2–5 slots | Every slot of lag is a slot of blockhash budget burned before submission |
| RPC p50 response (hot methods) | <15 ms | 50–200 ms | Bounds your reaction speed; slow RPC means slow bot regardless of code |
| RPC p99 during congestion | <60 ms | 500–2000 ms | Tail latency is where bots actually lose; averages hide the failure mode |
| Geyser event-to-detection lag | <20 ms | 100–300 ms (WebSocket) | Layer 4 metric; ground truth for whether you're firing on fresh data |
| Transaction success rate | >85% | 40–60% during congestion | Combines all four layers; if low, run the rest of the table to find which layer |
| Time to leader on sendTransaction | <30 ms | 100–400 ms (cross-region) | Layer 3 metric; geographic tax made visible |
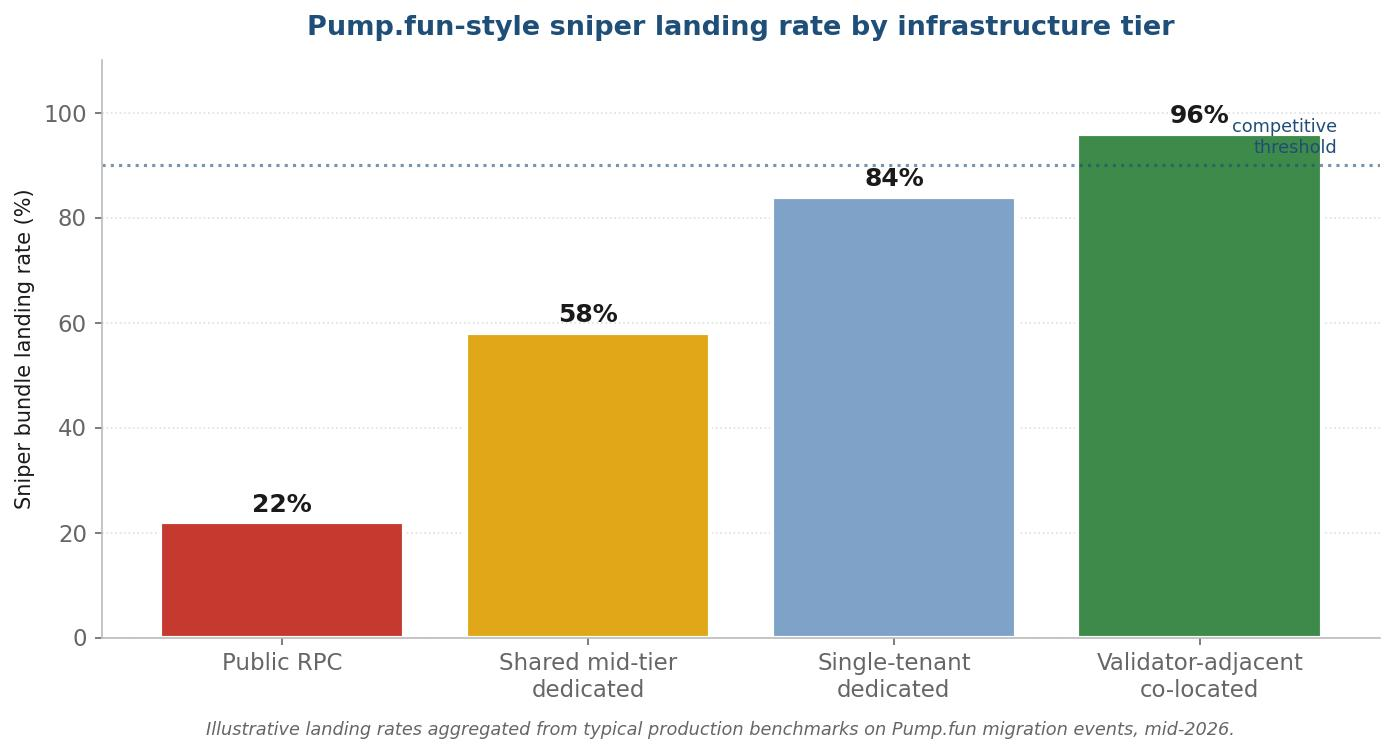
Notice the spread between typical shared-node values and competitive targets. A bot operating on the shared-node column isn't a worse bot—it's a bot operating on infrastructure that was never built for the workload. The fix is rarely the strategy. The fix is moving down the table toward the target column.
Strategy gets the credit. Infrastructure gets the result
Every sniper bot guide on the public internet eventually tells you the same things about strategy—token filtering, position sizing, rug protection, exit logic. Those things matter. But they all run downstream of the four infrastructure layers above. If Layer 1 fails, your detection is late. If Layer 2 fails, your bundle doesn't land. If Layer 3 fails, you can't reach the leader in time. If Layer 4 fails, you fired on stale data.
The bots in the top 10–15% of landing rate share one thing. They got all four layers right before they thought about the strategy. The bots in the bottom 85% are running the same strategies on stacks that were never built to compete.
Audit the four layers. Benchmark the metrics. Fix the one that's weakest first. That's the real sniper bot guide—and the part nobody else writes about.
Run the rpc-benchmark.ts script in this article against your current endpoint, then against RPC Fast. p50, p95, p99—see the difference in numbers before you commit.
.jpg)



.jpg)

