





.jpg)
TL;DR
- A Solana transaction crosses five stages: client build and sign, RPC submission, the leader TPU, block inclusion, and confirmation. Capital leaks at every one of them.
- Solana has no mempool. A transaction that fails to land does not wait in a queue. It is gone, and you only find out when you poll for a signature that never confirms.
- The quietest killer is the RPC to leader hop. On public endpoints, transactions are dropped before the leader ever sees them. SWQoS reserves 80% of the leader's TPU capacity for staked connections.
- processed, confirmed, and finalized are not interchangeable. Bots that gate on finalized wait roughly 12.8 seconds and forfeit the trade. Bots that act on processed act on transactions that can still vanish.
- RPC Fast benchmarks (Q2 2026): 0.3 median slot lag, 18ms getAccountInfo p99, 12ms Yellowstone gRPC arrival, 96.4% Jito bundle landing rate, 5000 sustained RPS, 99.99% uptime.
A Solana transaction succeeds or fails across five distinct stages, and each stage has its own failure mode. Stage one builds and signs it. Stage two submits it through an RPC node. Stage three hands it to the current leader's transaction processing unit. Stage four fights for inclusion in a 400ms slot. Stage five confirms it. Lose at any stage and the transaction does not retry on its own. It simply disappears, because there is no mempool to hold it.
Most teams debug the wrong layer. They tune strategy logic and raise priority fees while the real loss happens one or two hops earlier, on the network path that never reaches the leader. This guide walks the full lifecycle, names the exact place money leaks at every stage, and shows where the RPC layer decides the outcome before any of your code runs.
We tune this path for a living. The numbers in this article come from RPC Fast, a Solana-only RPC built by Dysnix on bare-metal nodes co-located with validators. Now the five stages.
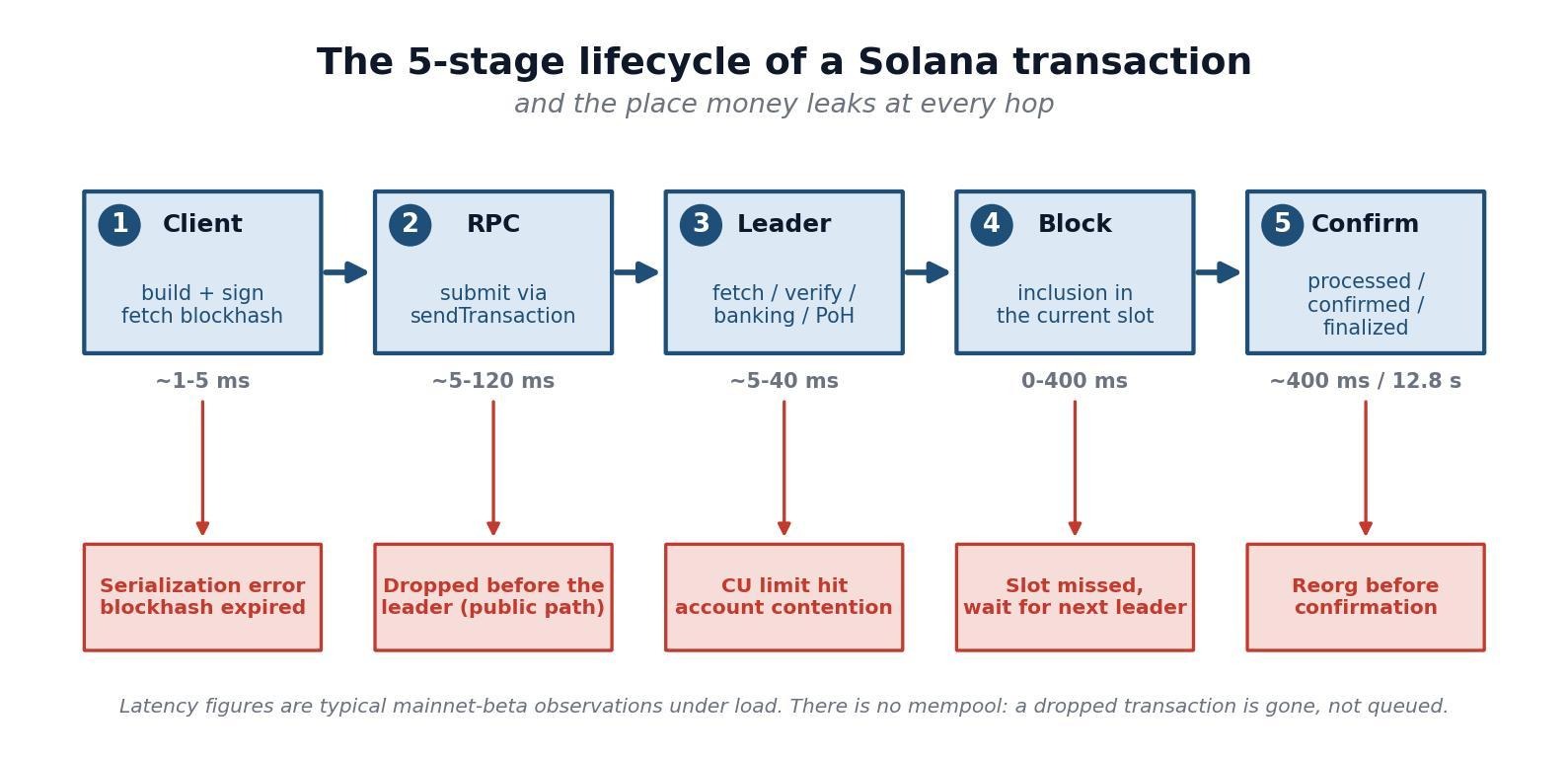
Stage 1. Client to RPC: serialization and a blockhash that already expired
Mini-answer: before a transaction leaves your machine it can already be dead, because the recent blockhash it references has a 151-slot shelf life of roughly 60 to 90 seconds.
Every Solana transaction carries a recent blockhash. It acts as a timestamp and a replay guard. The runtime accepts a transaction only while that blockhash is still inside its validity window, which is 151 slots deep. At a 400ms slot that is about 60 to 90 seconds of real time. Sign slowly, sit in a retry loop, or fetch the blockhash from a lagging node, and the transaction expires before it ever competes for a slot.
Two failure modes live here. The first is serialization. A malformed instruction, a wrong account order, a missing signer, or an oversized payload gets rejected at the client or by the RPC before it touches the network. The second is the expired blockhash. The fix for time-sensitive flows is to fetch the blockhash at the confirmed commitment and poll it often. For transactions that cannot be time-sensitive, such as treasury operations or multisig flows, the right tool is a durable nonce, which swaps the recent blockhash for an on-chain nonce that does not expire.
- Symptom: the transaction never appears on chain and getSignatureStatuses returns null.
- Root cause: expired blockhash or a client-side serialization reject, not congestion.
- Fix: confirmed-commitment blockhash, frequent refresh, durable nonces for non-urgent transactions.
Stage 2. RPC to leader: the hop where most transactions quietly die
Mini-answer: this is the single most expensive stage and the one teams ignore most. On a public endpoint your transaction competes for unstaked bandwidth and gets dropped before the leader ever reads it.
Once the RPC accepts your transaction it forwards it over QUIC to the current leader's TPU. Solana protects the leader from spam with Stake-Weighted Quality of Service (SWQoS). The leader reserves about 80% of its TPU connection capacity for traffic that arrives over staked connections, allocated in proportion to stake weight. The remaining 20% is the public lane, shared by every unstaked sender on the network.
That split is the whole game. When the network is calm, the public lane works. When volatility hits and bots flood the leader with duplicate transactions, the public lane saturates first and starts dropping packets. Your transaction never reaches the banking stage, so it never even enters the priority-fee auction. People respond by raising fees, but fees do nothing for a transaction that was dropped on the wire. Fee competition only happens among transactions that already arrived.
A staked connection changes the physics. An RPC peered with a staked validator forwards your transaction through reserved bandwidth that is held back before congestion starts. This is why a dropped-transaction problem is almost never a fee problem. It is a path problem. The mitigation is a staked submission path, optionally fanned out to several upcoming leaders, plus low-latency send infrastructure. That is exactly what a dedicated Solana RPC provider gives you that a public endpoint cannot.
.jpg)
Losing transactions before the leader sees them?
RPC Fast forwards your traffic over SWQoS-enabled staked connections from bare-metal nodes co-located with validators, so transactions reach the leader instead of dying on the public lane.
See the endpoints and benchmarks.
Stage 3. The leader: compute budget, account contention, and the fee floor
Mini-answer: the transaction reached the leader, but three resource limits can still reject it: the block ran out of compute, a hot account is contended, or your priority fee sits below the live floor.
The leader runs your transaction through the TPU, where it is fetched, signature-verified, scheduled, and executed before it lands in a block. Three things go wrong here.
Compute budget. Every transaction declares a compute-unit limit, and the block itself caps total compute at roughly 48M CU. Ask for more units than the transaction uses and you waste budget and pay for nothing. Ask for too few and the transaction fails mid-execution. During a busy slot the block fills, and well-formed transactions get bumped to the next one. Set an explicit limit with setComputeUnitLimit sized to your real usage, not the 200k default.
Account contention. Solana executes in parallel, but only across transactions that touch different writable accounts. Everyone writing to the same hot account, a popular AMM pool or a trending mint, serializes onto a single lane. A per-account compute cap throttles how much of the block any one account can consume. During a launch, contention on that account decides inclusion more than your fee does.
Priority-fee floor. Priority fees are micro-lamports per compute unit set with setComputeUnitPrice. The leader's scheduler favors higher bids per CU. During congestion the effective floor rises in real time, and a transaction priced below it gets skipped for higher bidders. Estimate the floor live with getRecentPrioritizationFees instead of using a static fee.
%201%20(1).jpg)
Stage 4. Block inclusion: miss the slot, lose the window
Mini-answer: leaders produce blocks in four-slot windows. Arrive a moment after a slot closes and you wait out the rest of that leader's window, which is dead time, not a retry.
A leader holds the right to produce blocks for four consecutive slots, then the schedule rotates to the next leader. Each slot is about 400ms. If your transaction lands at the leader just after a slot closes, it cannot be squeezed back in. It waits for the next available slot, and if the rest of the current leader's window is already full or contended, the realistic wait is the rest of that window before the next leader takes over.
For a passive transfer that delay is invisible. For an arbitrage or liquidation bot it is the difference between profit and a missed fill, because the price you were trading against has already moved. This is why event-to-submission latency matters more than raw throughput. The earlier you see the event and the faster your transaction reaches the leader, the more of the current slot you can still use.
%201%20(1).jpg)
Stage 5. Confirmation: processed, confirmed, finalized
Mini-answer: the transaction is in a block, but a block can still be dropped. Which commitment level you trust decides whether you act too early or too late.
Inclusion is not the end. Solana exposes three commitment levels, and they describe very different guarantees. processed means a single node has seen the transaction in a block that could still be skipped during a fork. confirmed means a supermajority of the cluster has voted for that block, so a reversal is highly unlikely. finalized means 31 or more blocks have been built on top, which makes it irreversible, but full finalization takes roughly 12.8 seconds today.
Bots burn capital at this stage in two opposite ways. Trust processed and you may act on a transaction that never actually lands, sending a follow-up trade against a state that rolls back. Wait for finalized and the opportunity is long gone before you confirm. The next section is the part most teams get wrong.
.jpg)
Processed vs confirmed vs finalized: why a trader should not wait for finalized
Mini-answer: for active trading, confirmed is the right level. It is fast enough to act on and safe enough to trust, while finalized is correct but too slow to trade on.
The instinct to wait for finalized comes from treating every transaction like a high-value settlement. Most trading flows are not that. They need a level that is unlikely to reverse and quick enough to keep the strategy alive. confirmed delivers both. A block with a cluster supermajority behind it almost never reverses, and it arrives in one to two seconds rather than thirteen.
There are real exceptions. Cross-program settlement of large balances, fiat off-ramps, and anything where a reversal is catastrophic should gate on finalized and accept the wait. The mistake is applying that bar to a momentum trade, where waiting 12.8 seconds means the edge evaporated ten seconds ago. Match the commitment level to the cost of being wrong, not to a habit.
| Commitment | Typical time | Guarantee | Use it for |
|---|---|---|---|
| processed | ~0.4 s | One node saw it, can still be dropped | UI hints, never for irreversible actions |
| confirmed | ~1-2 s | Cluster supermajority voted, near-final | Active trading, bots, most app logic |
| finalized | ~12.8 s | 31+ blocks on top, irreversible | Large settlements, off-ramps, accounting |
One forward note. The Alpenglow consensus upgrade, live on a community test cluster since May 2026 and targeting mainnet in the Q3 to Q4 2026 window, collapses this ladder toward a single deterministic finality around 100 to 150ms. When it ships, the confirmed versus finalized tradeoff largely disappears. Until then, the table above is how the network actually behaves, and confirmed remains the level traders should build on.
Where the RPC layer actually decides the outcome
Mini-answer: four of the five stages are decided by infrastructure you do not control from inside your bot. The RPC layer sets your blockhash freshness, your path to the leader, your latency to the slot, and your view of confirmation.
Read the five stages again and notice how little of the outcome lives in your strategy code. Stage one depends on how fresh a blockhash your RPC serves. Stage two depends entirely on whether you forward over a staked connection or the public lane. Stage four depends on how fast you saw the event and how close your submission path sits to the leader. Stage five depends on how quickly your RPC surfaces a confirmed status. Strategy quality matters, but it competes for a slice of the result that infrastructure has already narrowed.
This is the layer RPC Fast was built for. Dedicated bare-metal nodes co-located with validators, SWQoS-enabled staked submission, Jito ShredStream and Yellowstone gRPC for event arrival measured in single-digit milliseconds, and RPC Fast Beam for the fastest landing path. The point is not more features. The point is removing four of the five failure modes above before your code runs.
The benchmark table shows what that gap looks like in numbers. Public endpoints run several slots behind and drop transactions under load. Generic multi-chain providers do better but carry enough variance to fail when it matters most. A dedicated Solana-native path holds steady through congestion.
| Metric (Q2 2026) | Public RPC | Generic shared | RPC Fast |
|---|---|---|---|
| Median slot lag | 3-4 slots | 1-2 slots | 0.3 slots |
| Read p99 latency | 300-400 ms | 80-150 ms | 18 ms |
| gRPC event arrival | n/a | 40-90 ms | 12 ms |
| Jito bundle landing | low / variable | 70-85% | 96.4% |
| Sustained RPS | rate-limited | 1-2k | 5000 |
| Uptime (90d) | best effort | 99.9% | 99.99% |
None of this replaces a good strategy. It clears the ground so your strategy is the thing that decides the trade, instead of a dropped packet on a saturated public lane. Map your own losses to the five stages above, find the stage that is bleeding, and fix that one first. In most cases it is stage two.
Want to know which stage is costing you?
RPC Fast gives you fast, stable RPC nodes out of the box. No setup marathon, no leaking latency.
➜ Start for free.jpg)



.jpg)

