






TL;DR
• Sub-millisecond Solana HFT is won at the infrastructure layer—bare-metal colocation, multi-feed ingestion (Jito ShredStream + bloXroute OFR + Yellowstone gRPC), parallel transaction submission.
• Public RPCs and shared cloud endpoints lose 100–300ms before the bot even sees the market. That gap is the difference between a profitable strategy and one that gets sandwiched.
• Our managed stack (Dysnix DevOps + RPC Fast infrastructure) answers light methods such as getSlot in roughly 2–3ms and heavy account reads in 25–35ms, with 90%+ tx inclusion rates and 40% faster data cycles vs unmanaged setups.
• Trade-offs are real: a bare-metal pro setup with us runs $2,200–$4,000/month with the server, setup and maintenance included, and the latency edge typically captures fees worth 10x the bill in volatile markets.
• This playbook walks through the full stack: hardware selection, colocation strategy, feed integration, transaction routing, parallel submission, risk mitigation, and what RPC Fast handles for you.
High-frequency trading on Solana is a high-stakes game where milliseconds mean millions. Spot an arb between DEXs? Your bot signs the tx in a flash—but if it takes 200ms to propagate through gossip, some colocated ninja just ate your lunch.
Solana's blistering 65,000 TPS is a trader's dream, but its leader rotations and Turbine shreds turn latency into a beast. Sub-1ms reactions aren't optional; they're your moat against the pack. This playbook cuts through the noise, delivering a battle-tested setup to outpace the network—powered by Dysnix and RPC Fast's infra magic.
We'll cover the stack: bare-metal colocated servers, feeds that snag shreds early (Jito, bloXroute, Yellowstone), submission tricks for first-slot lands, and parallel blasts to hedge your bets. Plus, real talk on trade-offs like MEV risks and costs.
Powered by Dysnix and RPC Fast infrastructure and DevOps services
Let's cut to the chase: high-frequency trading on Solana isn't won on clever strategies alone—it's decided in the trenches of your infrastructure. We're talking sub-millisecond reaction times where every tick counts, and transactions that don't just submit but land in the slot like clockwork.
As a dedicated Solana RPC provider backed by Dysnix's battle-hardened DevOps muscle, we've tuned hundreds of these beasts for the Solana wild west. And yeah, it's possible to Frankenstein your own latency monster by stacking services like bloXroute's relays, Jito ShredStream for shred-grabbing wizardry, low-latency sends, and Yellowstone's gRPC streams for that structured data flow. Toss in some colocation and kernel tweaks, and you're golden... or at least, 30–500ms faster.
But here's the kicker: those gains don't come free. You'll wrestle with costs that stack up like unpaid gas fees, trade-offs like dipping into centralized relays (hello, MEV sandwich risks), and the sheer brain-melt of keeping it all humming as Solana's leaders shuffle like a bad poker game.
That's where we shine—our managed services abstract the chaos, letting you chase alpha without debugging network variance at midnight. Stick around; we'll unpack the full stack next.
Building the infrastructure foundation with bare-metal servers and tuning
This foundation layer is where we strip away the fluff: no shared cloud tenants fighting for cycles, just raw, tuned horsepower colocated where the action happens. RPC Fast (with Dysnix's DevOps chops) provisions and maintains this beast, so you get sub-1ms local latencies without the headache of racking servers yourself.
Selecting hardware for peak performance
Start with the silicon that doesn't flinch under pressure. We're talking bare-metal servers specced for Solana's shred-parsing marathons and tx-signing sprints—nothing virtualized, because who needs a neighbor's Netflix stream jacking your CPU?
RPC Fast hooks you up with the latest AMD EPYC TURIN 9005 series or the workhorse AMD EPYC GENOA 9354, loaded with 512GB to 2.3TB of RAM. Why these? EPYC's massive core counts (up to 192 threads) chew through parallel workloads like gossip propagation or bundle validation without breaking a sweat, while the RAM hoard keeps hot data in cache, slashing I/O waits. In our tests, this setup handles 10,000+ TPS ingestion spikes with <0.5ms variance—think of it as giving your bot a Ferrari engine instead of a golf cart.
Choosing optimal locations for colocation
We colocate your servers inches from these constellations: Frankfurt, London, and New York datacenters like OVH, Latitude, Equinix, and TeraSwitch. These spots aren't random; they're sweet spots for peering with bloXroute's SWQoS (that software-defined routing magic) and Jito's relays, trimming propagation by 20–50ms on average.
Tuning and maintenance for sustained low latency
Hardware's great, but untuned? It's like a Ferrari in traffic. Our engineers dive in post-provisioning, optimizing the node config for Solana's high-throughput quirks: cranking throughput to 100k+ shreds/sec while ironing out latency tails.
We slash base network jitter with kernel tweaks—sysctls for TCP buffers, irqbalance for NIC interrupts, even custom eBPF filters to prioritize Solana traffic. Then layer on chain-specific sauce: faster Merkle proofs, optimized Turbine fanout. For monitoring, we wire in the A-team: Jito ShredStream gRPC for raw leader shreds (bypassing gossip entirely), Yellowstone gRPC for filtered account/slot streams, bloXroute TX streamer for tx alerts, and OFR shred parsing for relay-fed blocks. Continuous benchmarking (our proprietary probes hit every 15min) keeps things adaptive as Solana's leader schedule dances.
Round it out with proactive alerts (Slack/Telegram pings for sync drifts >5s) and full managed ops: we handle health checks, failover swaps, and upgrades 24/7. Sync issues? Network blips? We squash 'em before your bot notices.
With RPC Fast, your infra hums at peak—frees you to tweak strategies, not babysit uptime.
Stop building your own latency stack.
Production-grade Solana HFT infrastructure as a SaaS plan, wired and tuned. Start in minutes, not weeks.
→ Start for freeIngesting market data faster with advanced feeds
Alright, you've got your beast of a server humming in the right spot—now it's time to feed it the freshest data without the Solana gossip mill slowing you down. Think of market data ingestion as your bot's morning coffee: if it's stale, your whole strategy's groggy and missing the pump. Solana's Turbine protocol shreds blocks into packets and gossips them out, which is efficient for the chain but a latency nightmare for HFT—standard setups can lag 100–300ms while shreds hop from validator to validator like kids in a game of telephone.
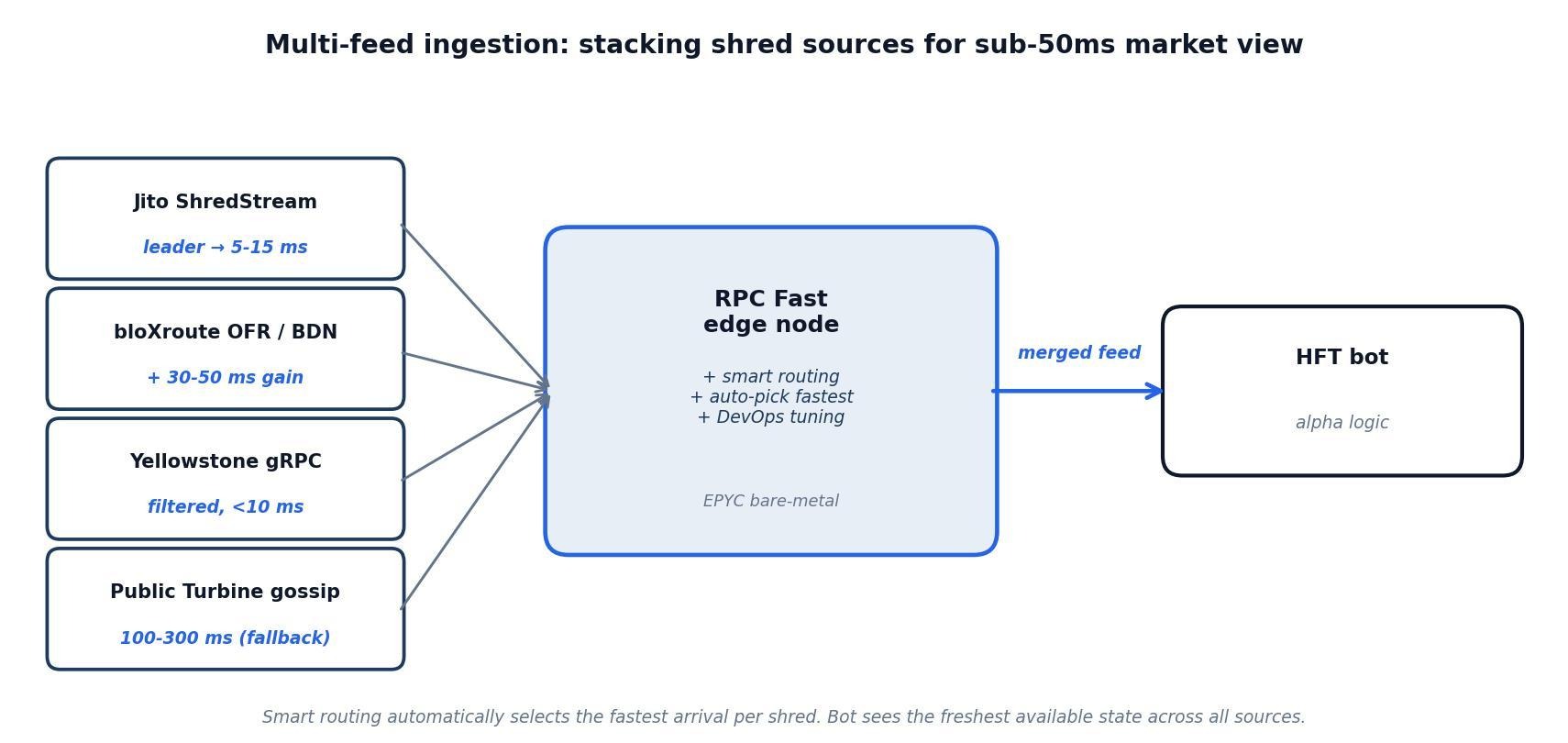
The fix? Specialized feeds that intercept shreds at the source, delivering them direct to your node for that sub-50ms edge. We'll unpack the top players, how they work, and why stacking them smartly turns your bot into a clairvoyant.
Understanding shred propagation and why speed matters
Shreds are Solana's secret sauce: blocks get diced into 1KB chunks for faster dissemination, but default p2p gossip means your node might wait cycles for the full picture. For HFT, that's death—spot a perp liquidation or DEX arb? You need those shreds parsed now to sign and submit before the slot flips. Faster ingestion isn't just bragging rights; it's profit: shave 200ms off data arrival, and you're front-running the herd on volatile plays like memecoin flips. Pro tip: always layer these feeds atop your tuned infra, because even the best relay flops if your server's choking on bad NIC drivers.
Jito ShredStream: Direct access to leader-produced shreds
Jito's ShredStream is the VIP line to the action—straight gRPC feeds of shreds fresh from the leader's oven, no gossip middleman. Traders using it peek at block data up to 270ms ahead of a Yellowstone gRPC subscription, perfect for bots that need raw shreds to simulate outcomes or trigger MEV bundles on the fly.
How it works: Subscribe via gRPC, and it streams pre-validation shreds for instant parsing—your node reconstructs blocks without the network's chit-chat. It's a game-changer for high-stakes plays, but heads up: it's tied to Jito's ecosystem, so bundle your txs through them for max synergy. In our playbook, we default-wire this for clients chasing that "see it first" alpha.
bloXroute OFR and BDN: Global relay for optimized delivery
Enter bloXroute's Open Fabric Relay (OFR) and Blockchain Distribution Network (BDN)—a worldwide mesh of low-latency relays that snatch and sprint shreds to your node, netting 30–50ms gains over vanilla propagation. It's like upgrading from economy to business class: their SWQoS prioritizes your traffic across private paths, dodging public net congestion.
That said, according to our internal benchmarks, Jito edges it out in raw speed for most Solana setups—Jito's direct leader ties give it the nod, though bloXroute shines in global diversity (catching edge-case leaders better). No native gRPC here, so options are binary:
- TX Streamer: For transaction-only alerts—quick and dirty, but skips full shreds.
- Independent Shred Parsing: Feed OFR shreds straight to your parser, mimicking how a Solana node gulps them (great for custom logic, but adds a smidge of overhead).
We love pairing it with Jito for redundancy—more on that below.
Yellowstone gRPC: Structured streams for strategy integration
Yellowstone, the Geyser plugin darling, flips the script from raw shreds to polished streams: filtered gRPC feeds for accounts, slots, and txs, all under 10ms local latency once tuned. It's your strategy's best friend—pipe it into dashboards for real-time viz, or feed it logic for conditional trades without drowning in unfiltered noise.
Why it rules for HFT: Custom filters mean you only get what matters (e.g., price changes on specific pools), slashing compute waste. Trend alert: Many teams are ditching the "Solana node + Yellowstone" combo for pure Jito ShredStream to skip node sync entirely—fewer moving parts, faster reactions.
Smart integration and routing with RPC Fast
At RPC Fast, we don't just throw feeds at the wall—we integrate exactly what your playbook needs, benchmarked for peak efficiency against your specific reqs (arb volume? MEV focus? We got you). Smart routing kicks in automatically: Jito ShredStream and bloXroute OFR shove shreds to your node plus p2p Turbine, and it auto-picks the quickest arrival. Boom—best-of-breed without the glue code headache.
Want to level up? Our DevOps squad sets this during onboarding, with ongoing tweaks as Solana evolves. Clients see 40% faster data cycles out the gate, letting bots react like they have a time machine. No more "why'd my edge vanish?"—just clean, colocated ingestion that scales with your ambition.
One capability worth knowing about sits on the shared side: Aperture TxStream attaches a predicted execution result to each transaction while it is still in flight, before it lands, reconstructed from the same deshredded data — around 95% accurate against actual execution, at a cost of roughly 791µs to median delivery. It is included on the Aperture plan, and on Stream TxStream is available for a limited time without simulation.
Submitting transactions to land first in the slot
Data's in, strategy's lit—now the real adrenaline hits: firing off that tx before the slot slams shut. In Solana's world, it's not enough to submit; you gotta land first, or you're just another also-ran in the mempool scrum. Leaders only pack so many txs per 400ms window, and with bots swarming like sharks at a chum bucket, delays mean your arb gets sandwiched or dropped.
The mechanics of Solana transaction inclusion
Quick primer: Txs hit the leader via RPC or relays, get queued, and if they're timely (fresh blockhash) and prioritized (tips, bundles), they slot in. Miss the window? Retry city, with expiry risks and gas bleed. HFT twist: Congestion spikes (hello, pump.fun frenzies) turn it into a race—first to leader wins the block space. Tools here don't just send; they prioritize and protect, stacking 50–100ms edges that compound into serious alpha. Pro move: Always sign with durable nonces for retries, but lean on bundles to atomize multi-step plays without front-run roulette.
Jito Low Latency Transaction Send and Block Engine
Jito's your MEV bodyguard and express lane in one: Low Latency Send (or Block Engine submission) blasts txs direct to leaders with priority fees and bundle magic for atomic execution. Dreaming of a sandwich-proof arb? Bundle your buys/sells—Jito auctions them as a unit, shielding against insertions and landing under 50ms in hot slots.
It's tailor-made for MEV-aware trading: Tip the bundle higher, and builders prioritize it in the "block space lottery." We've seen clients double inclusion on perps via this—pure velocity. Downside? RPS caps on bundles, so pair it with volume tools. RPC Fast wires it seamless during setup; our engineers even sim your load to dial tips dynamically.
bloXroute Trading API: Fast propagation with MEV protection
Shoutout to our bloXroute partnership—it's like giving your txs a SWQoS fast-pass through the network. The Solana Trading API isn't your grandma's RPC: It propagates with such fury that 83% land first vs. public endpoints, thanks to private mempools and optimized routing that dodges gossip jams.
Bonus: Built-in MEV shields keep searchers at bay, so your liquidations or market-makes stay stealthy. For HFT crews, it's a no-brainer—blazing speed without the reorg roulette. We bundle this into client stacks, benchmarking against Jito to pick the winner per region. Clients rave: "Turned our 20% drop rate into 90% lands overnight." If you're eyeing high-value plays, this API's your edge multiplier.
Enhancing with colocation peering
Don't sleep on the basics: Your colocated servers (from our foundation layer) peer direct into leader hubs, shaving 10–20ms off the final hop. It's the multiplier—Jito or bloXroute txs arrive not just fast, but there faster, queuing up for that golden first-slot shot.
Result? Txs hit leaders early, inclusion odds skyrocket, and your bot's not left twiddling thumbs on retries. We handle the peering handshakes during provision—Equinix cross-connects, anyone?—so it's plug-and-play.
Balancing trade-offs in low-latency setups
No silver bullet in HFT—every ms gained costs something, and ignoring the fine print turns your setup into a house of cards. We've battle-tested these stacks, so here's the real talk: the pitfalls, and how RPC Fast smooths 'em out. Speed's addictive, but sustainable speed wins wars.
Key trade-offs to weigh:
- Centralization & MEV exposure: Leaning on Jito or bloXroute ties you to their relay empires—great for speed, but it funnels you into their MEV pools. One outage or policy shift, and your bot's sidelined. Mitigation? Diversify endpoints (more on parallel submission next), and audit for sandwich risks. We rotate relays in client configs to keep you neutral.
- Cost creep: Bare-metal beasts, colo racks, and premium feeds? Not pocket change, but not five figures either—our dedicated Solana nodes run $2,200–$4,000/month depending on tier and region, with the server, setup and maintenance included and no setup fee. But flip it: In Solana's vol, that 100ms edge captures fees worth 10x the bill. RPC Fast's tiers make it ROI-transparent; we benchmark your payback period upfront.
- Complexity overload: Wiring feeds, tuning peers, and monitoring leader drifts? It's a full-time gig without the right crew. That's us—full DevOps + infra management abstracts the mess, with dashboards that flag issues before they bite. Clients focus on code; we handle the ops alchemy.
Bottom line: These aren't bugs; they're features of pushing limits. With our managed layer, trade-offs shrink to footnotes, letting you scale without the soul-crush.
One trade-off worth naming before the setup steps: you do not have to start on dedicated hardware.
RPC Fast sells more than one line. Shared SaaS plans start at $0 with no card, which is enough to build a bot and prove a strategy before you pay for metal — current limits are on the pricing page.
Dedicated Solana nodes start at $2,200/month with the server, setup and maintenance included and no setup fee, delivered within 72 hours. That is the line this playbook describes.
The cheap next step is the free plan. Move to dedicated when shared rate limits, rather than the network itself, become the thing costing you slots.
Recommended step-by-step setup for Solana HFT

Follow these steps, and you'll be landing txs like a pro before your coffee's cold:
- Provision bare-metal high-performance servers in leader-adjacent data centers—handled end-to-end by RPC Fast.
- Enable Jito ShredStream (or bloXroute OFR) for the fastest data ingestion—integrated by default during node setup.
- Activate Yellowstone gRPC for structured feeds—also default-integrated in the node setup.
- Route transactions via Jito Block Engine or bloXroute Trader API.
- Tap RPC Fast engineers for continuous benchmarking and performance tuning via dedicated channels.
- Scale horizontally with multi-region redundancy, if needed.
Implementing parallel submission for redundancy and speed
Ever feel like your tx is playing Russian roulette with the leader schedule? One flaky relay, one spike in congestion, and poof—your arb's toast. Enter parallel submission: the HFT equivalent of shotgun-blasting that signed tx across every endpoint in your arsenal. It's not overkill; it's insurance.
By fanning out to multiple RPCs and relays at once, you crank inclusion odds while dodging single-path pitfalls like expiry hiccups or transient drops. Handle the basics—blockhash freshness, dedup via signatures, and status polling—and it's a net win.
RPC Fast bundles this natively: Our dedicated nodes, bloXroute Trading API, and Jito Block Engine fire in unison, so you get the full shotgun without the reload time. Clients see p99 latencies plummet 30–50%—let's unpack why and how.
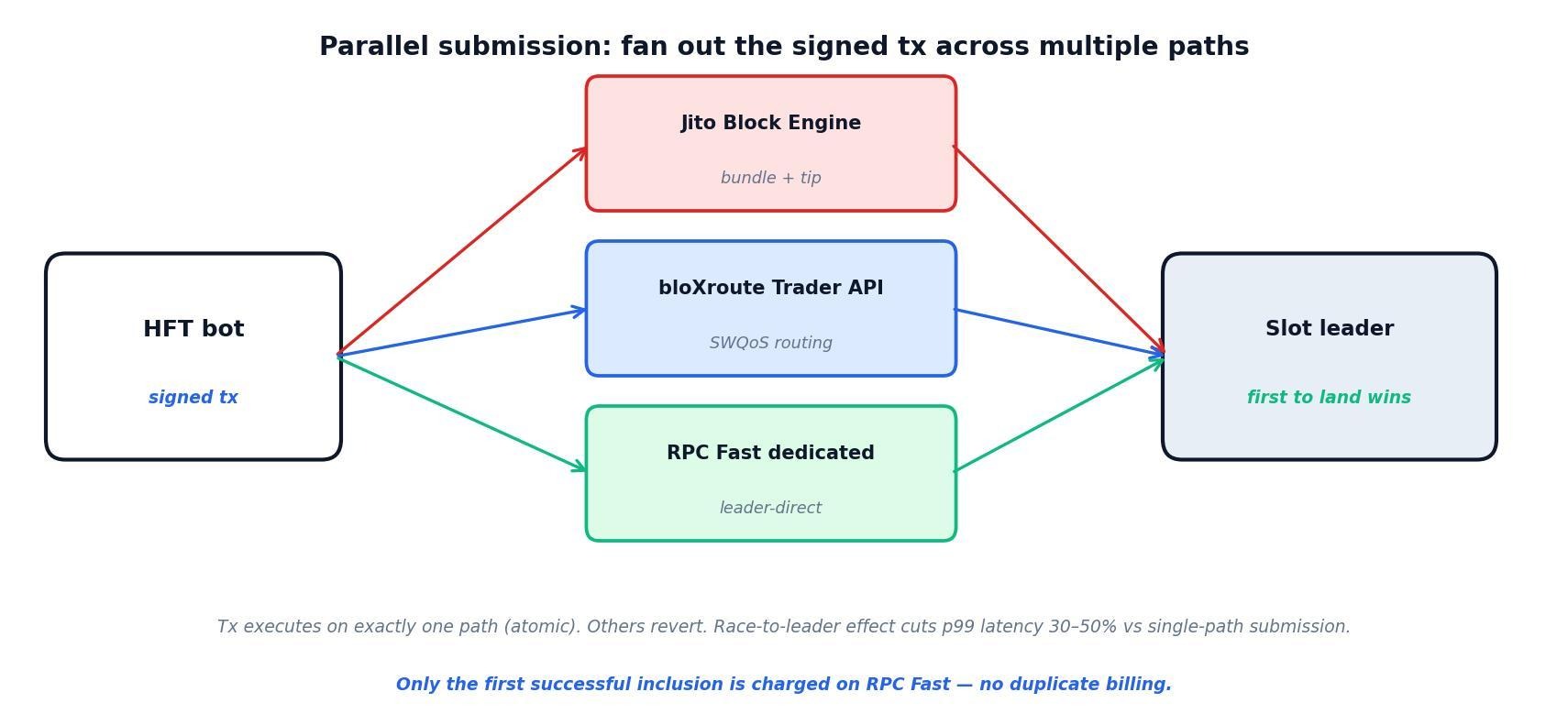
Why broadcast to multiple endpoints?
It's simple math meets network chaos: Solana's leaders shuffle globally, and no single path owns the fast lane every slot. Parallel play exploits that, turning variance into velocity. Here's the breakdown:
- Multiple network paths for lower tail latency: Different RPCs and relays flaunt unique peering, geo-placements, and routing wizardry to validators. Hitting several slashes p95/p99 propagation to the leader via the classic race-to-leader effect—your tx bolts down the quickest trail while backups hedge the slow ones. The tx only executes on one (failing/reversing elsewhere, zero dupes), and most charge per success. Caveat: Watch RPC rate limits anyway—they bite regardless of wins.
- Diverse relayer ecosystems snag varied leaders: Jito, bloXroute OFR, or private relays pack direct/private hops or trader-tuned routes; parallel sends cherry-pick the hottest path to the current boss. It's like polling your sharpest scouts—whoever spots the alpha first, you pounce.
- Race sharpens inclusion vs. queue/MEV dogfights: Contested slots? The first node (or relay handing priority tx to a builder) claims the throne. Broadcasting flips latency from liability to superpower—your tx isn't queuing; it's charging.
In short: It's redundancy with rocket fuel. No more "that one relay ghosted me"—just reliable lands, even in pump.fun frenzies.
Quick checklist to implement parallel submission today
Ready to wire it? Grab 3–5 endpoints (mix RPCs + relays like Jito/bloXroute), and follow this:
- Pick your squad: At least one leader-savvy relay (Jito or bloXroute—peek docs.bloxroute.com for endpoints). Add your dedicated RPC and a geo-diverse backup.
- Fan out the signed tx: Parallel POSTs to all—no sequencing needed. Libraries like Rust's Tokio or JS async make it a breeze.
- Track and trim: Hook sendTransaction confirmations + getSignatureStatuses. Kill after first "accepted," then poll finalization. Log latencies for tweaks.
- Benchmark the beast: Hammer under load (congested vs. quiet nets) for p50/p95/p99 stats. Tools like our RPC Fast probes automate this.
- Nonce it up: Slap durable nonces for multi-minute retries—essential if slots slip.
Boom—deploy in an afternoon, edge in hours. We handle the orchestration if you want zero-fuss.
Risks and mitigations
Parallel's a force multiplier, but like any blitz, it packs pitfalls. We've ironed 'em in client runs—here's the scorecard:
- Cost & rate limits: Multi-sends amp usage (and bills) across paid tiers; throttle hits if you're blasting blind. Fix: Budget via scalable plans like ours—monitor with per-path quotas. RPC Fast dashboards flag overages pre-bill.
- Bigger attack surface & centralization traps: Too cozy with one relay? Redundancy crumbles on their outage; diversify or die. Plus, MEV lurks—relayers might reorder for their cut. Counter: Rotate endpoints quarterly, audit exposure with sims. We bake in multi-relay rotation, keeping you decentralized without the dev drudge.
- False positives on "accepted": Some RPCs greenlight locally but ghost before leader handoff—always chase with getStatus or fork checks. Our monitoring auto-verifies, pinging alerts on drifts.
Net: Risks are real but routinized—parallel nets 80–90% inclusion for our crews, with safeguards that turn gotchas into footnotes. Dial it in, and you're not just faster; you're unbreakable.
Quick checklist to try this today
Wiring parallel submission doesn't have to be a slog—grab your endpoints, fire up a test script, and benchmark the magic. This numbered rundown gets you from zero to racing in an hour; we've scripted it for clients in Rust/TS if you ping us. Follow along, and watch those inclusion rates climb.
- Pick 3–5 endpoints (include at least one leader-aware relay: Jito or bloXroute). docs.bloxroute.com
- Implement parallel fan-out of the same signed tx to all endpoints.
- Listen for sendTransaction acceptance + getSignatureStatuses. Stop after first accepted and track finalization.
- Repeat under different network conditions and collect p50/p95/p99.
- Add durable nonce if you require multi-minute retry windows.
Why choose RPC Fast for your Solana HFT infrastructure?
At RPC Fast, fused with Dysnix's DevOps sorcery, we're not just providers; we're the co-pilots who've tuned 100+ bots to outgun the field. Our secret? DeFi-native smarts meet bare-metal brute force, all wrapped in partnerships like bloXroute for that SWQoS turbo and Jito for bundle boss-levels.
What sets us apart:
- End-to-end mastery: From provisioning EPYC colo kings to wiring ShredStream/Yellowstone feeds and parallel tx blasts, we own the stack. No vendor ping-pong— one team, zero silos. Clients hit 40% latency trims from launch, with light methods like getSlot answering in roughly 2–3ms and heavy account reads in 25–35ms.
- Adaptive edge: Continuous benchmarks track leader drifts and net flux, auto-tweaking for Solana's chaos. Proactive alerts? 24/7. Automatic failover? Included, with 99.99% uptime. It's physics-maxed, so your alpha hunt's uninterrupted.
- MEV & risk armor: We diversify relays out the gate, shielding against exposure while stacking inclusion to 90%+. Unlike fragmented plays, our managed ops turn complexity into "set it once, profit forever."
Questions about your low-latency setup?
RPC Fast engineers answer them in the chat.
Join the RPC Fast Solana chat.jpg)





