






You already see the parent trade. Your bot computes the backrun. And then your transaction lands one slot too late. On Solana, “almost fast enough” means your edge is gone. The gap is not your strategy. It is your infra: RPC placement, relay paths, swQoS, and how you submit transactions into the leader’s slot.
This article breaks down what same-block execution really requires on Solana, what the latest public benchmarks tell you about realistic speeds, and two concrete architectures:
- An advanced single-path stack that many teams run today.
- An HFT-grade, multi-path design, with RPC Fast as a reference implementation.
The goal is simple: help you decide whether your current setup can support “same-block with parent” and p99 latency in the sub-100 ms range, and what it would take to get there.
TL;DR
- Same-block landing is usually lost in the gaps between signal detection, relay choice, slot timing, and how your transaction reaches the leader.
- Priority fees and Jito tips do not win on their own. The edge comes from path quality: swQoS relationships, relay diversity, shred visibility, and proximity to where ordering decisions happen.
- A single polished execution path looks efficient until volatility hits. Then p99 behavior, not average latency, decides whether profitable setups land in-slot or turn into next-slot leftovers.
- The real separation point is architectural: one-path stacks are enough for many bots, but same-block trading starts demanding parallel submission, path-level observability, and failure isolation.
- The strongest setups do not treat RPC as a request endpoint. They treat it as a routed execution layer with independent feeds, independent submit paths, and constant measurement of slot-level outcomes.
- If you are not logging parent slot, child slot, submit time per path, and landing order, you are likely blaming the strategy for losses created by infrastructure variance.
Every Delivery Path.
One Endpoint.
All three accessible through one endpoint.
No separate accounts. No separate API keys.


Astralane
bundle support + mev_protect routing

bloXroute
3 tip accounts, bundle + sandwich protection

Falcon
5 tip accounts, pure fastest-mode delivery
What “same-block” means on Solana for trading
For infra and trading teams, “same-block” on Solana usually collapses into two separate targets.
Same-block relative to a specific parent transaction
You want your transaction to:
- Execute after a known parent tx;
- In the same slot;
- With deterministic account ordering.
Examples:
- DEX arbitrage: Parent is a large swap on Raydium; child is your hedge or backrun on another pool;
- Liquidation: Parent is a collateral price move; child is your liquidation transaction;
- TWAP (Time Weighted Average Price) / VWAP (Volume Weighted Average Price) strategies: Parent is a larger on-chain move you want to react to atomically.
Jito bundles are the primary mechanism here. A bundle is a list of up to 5 transactions that execute sequentially and atomically within a single slot. If any transaction fails, the whole bundle is discarded.
For a same-block relative to a parent, you usually:
- Construct a bundle where the parent transaction and your child appear in strict order, or
- React to a parent observed in pre-confirmation shreds and construct a new bundle that relies on that state transition.
Reacting to a pre-confirmation parent means acting before you know whether it succeeded. RPC Fast’s Aperture TxStream narrows that gap: it attaches a predicted execution result to each transaction while it is still in flight, reconstructed from deshredded data, running around 95% accurate against actual execution at roughly 791 µs added to median delivery. Simulation is included on the Aperture plan; TxStream on the Stream plan runs without it.
A p99 end-to-end latency budget, such as <80 ms
Here, latency means: From “signal”: event detected (e.g., book delta, shred content, parent TX)—to “landed”: your transaction included in a block and visible in your observability pipeline. An example of a simplified latency budget might look like this:
These numbers are internal to optimized stacks, not public mainnet benchmarks. Public reports talk about seconds. HFT teams care about whether their internal pipeline maintains low-double-digit ms p99 under normal conditions.
How a Solana transaction moves–and where it slows down
Every Solana transaction hits most of these steps:
- Your bot / strategy detects a signal;
- Local signer builds and signs a transaction or bundle with a recent blockhash;
- Transaction goes to an RPC or relay over QUIC or TCP;
- RPC / relay forwards it towards the current and upcoming leaders:
- SwQoS decides which connections get bandwidth priority;
- Priority fees and Jito tips influence queue ranking and MEV auctions.
- Leader verifies, locks accounts, executes, and packs transactions into shreds;
- Shreds propagate through the Turbine; validators vote; the block finalizes;
- Your infra picks up inclusion via shreds, RPC, or gRPC feeds.
Latency and variance enter at:
- Geo distance and network path to leaders;
- Whether your RPC has swQoS and stake-weighted priority;
- Whether you are sending to leaders directly (e.g., Jito Block Engine) or through a generic public RPC;
- How fast you see new shreds and confirmation.
The node/RPC layer is where providers like RPC Fast and infra teams like Dysnix focus: tuned validators/RPCs, colocation, and wired-in relays. RPC Fast covers that layer on two tracks: shared SaaS plans that start on a free Start tier at $0 with no card, and dedicated bare-metal Solana nodes from $2,200/month with the server, setup and maintenance included, delivered within 72 hours.
The Submission Path, Explained

1

Check the provider-scores WebSocket to pick the best provider
2

Append the provider tip instruction and sign your transaction
3

POST sendTransaction to beam.rpcfast.com with your chosen provider + mode
4

BEAM routes it through that provider's low-latency stack (SWQoS / Jito)
5

Track landing via the score feed and dashboard latency metrics
What public benchmarks say about “fast” on Solana
Public data does not cover true HFT same-block stacks, but it tells you what “fast” looks like for serious users on mainnet today.
Chorus One: swQoS, priority fees, and Jito tips
Chorus One analyzed the effects of stake-weighted QoS (swQoS), priority fees, and Jito tips on inclusion time in their report. Key findings from their observations:
- Most users fall into “normal” and “slow” categories, with time to inclusion in the 10s–60s range;
- Priority fees alone have limited correlation with lower inclusion times;
- Jito tips alone also do not guarantee any fast landing;
- swQoS (trusted, stake-weighted connections between RPCs and validators) materially reduces time to inclusion, especially for “slow” users.
Takeaway:
- Without swQoS and well-placed infrastructure, even “high-fee” transactions often land in seconds
- Beating seconds and getting into consistent sub-second behavior already places you ahead of the majority of traffic
bloXroute: Solana Trader API benchmarks
bloXroute’s 2025 benchmarks for their Solana Trader API compared different endpoints (including their swQoS mode, FastBestEffort mode, Temporal/Nozomi, NextBlock, and Jito Direct) using Raydium swaps. Here’s what we find interesting:
These numbers are strong for pro traders using low-latency infrastructure, but they are still in the seconds range, not tens of milliseconds.
The gap:
- Public multi-endpoint benchmarks: p90 in ~1–2 seconds range;
- HFT same-block goal: p99 internal pipeline in low-double-digit ms, plus correct same-slot ordering relative to a parent.
Your infrastructure and architecture choice decide whether your stack behaves like the public benchmarks or closer to internal HFT expectations.
Two architectures for same-block Solana trading
Most teams we meet land in one of two buckets.
Architecture A: Advanced single-path stack
This is where many serious bots and smaller MM desks live today.
Core components
- One or a few high-performance nodes (bare metal or large VMs) in 1–2 regions;
- One main Solana RPC service or/and validator, tuned for throughput;
- One main MEV / relay path, often Jito Block Engine;
- One structured market-data channel (e.g. Yellowstone gRPC).
Data flow example
- Ingestion: Turbine + Geyser plugin feed the node; Yellowstone gRPC streams filtered accounts/slots to your strategy;
- Execution: Strategy detects opportunity → signs tx/bundle → sends via Jito Low Latency Transaction Send or through the primary RPC.
Strengths
- Simpler to reason about and operate
- Good p50 / p95 latency for most non-HFT bots
- Lower integration and monitoring overhead
Limits for same-block and tight p99
- A single relay or RPC path is a single point of tail-latency failure;
- Under heavy spam or congestion, p99 can drift into multi-second territory;
- Same-block relative to a hot parent often degrades into “next slot” during memecoin and airdrop frenzies;
- You often do not have explicit SLOs or visibility per path.
Typical symptoms
- Most days, strategies work fine;
- During hot events, you see profitable opportunities that your sim picked up, but post-mortem shows your child tx in the next slot or several slots later.
Architecture B: HFT-grade multi-path stack (RPC Fast-style)
This architecture targets desks where missing a same-block opportunity has a clear P&L impact. RPC Fast’s low-latency Solana playbook is one concrete implementation pattern.
Core design
- Bare-metal, colocated servers in leader-dense regions
- Examples: Frankfurt, London, New York, in DCs with strong peering to Solana validators and relays
- Validator / RPC layer tuned for:
- High shreds-per-second throughput
- Low jitter networking (IRQ tuning, TCP parameters, NIC offloads)
- Feeds:
- Jito ShredStream for near-leader shreds;
- bloXroute OFR and Trader API for global propagation diversity;
- Optional Yellowstone gRPC, or in some setups, replaced by direct ShredStream consumption to skip full node sync.
- Execution:
- Parallel submission of critical transactions to:
- Jito Low Latency Transaction Send / Block Engine
- bloXroute Trader API endpoint(s)
- One or more staked RPCs with swQoS configured
- Deduplication and status tracking to avoid double-spend errors and reduce self-spam.
- Parallel submission of critical transactions to:
Where RPC Fast fits
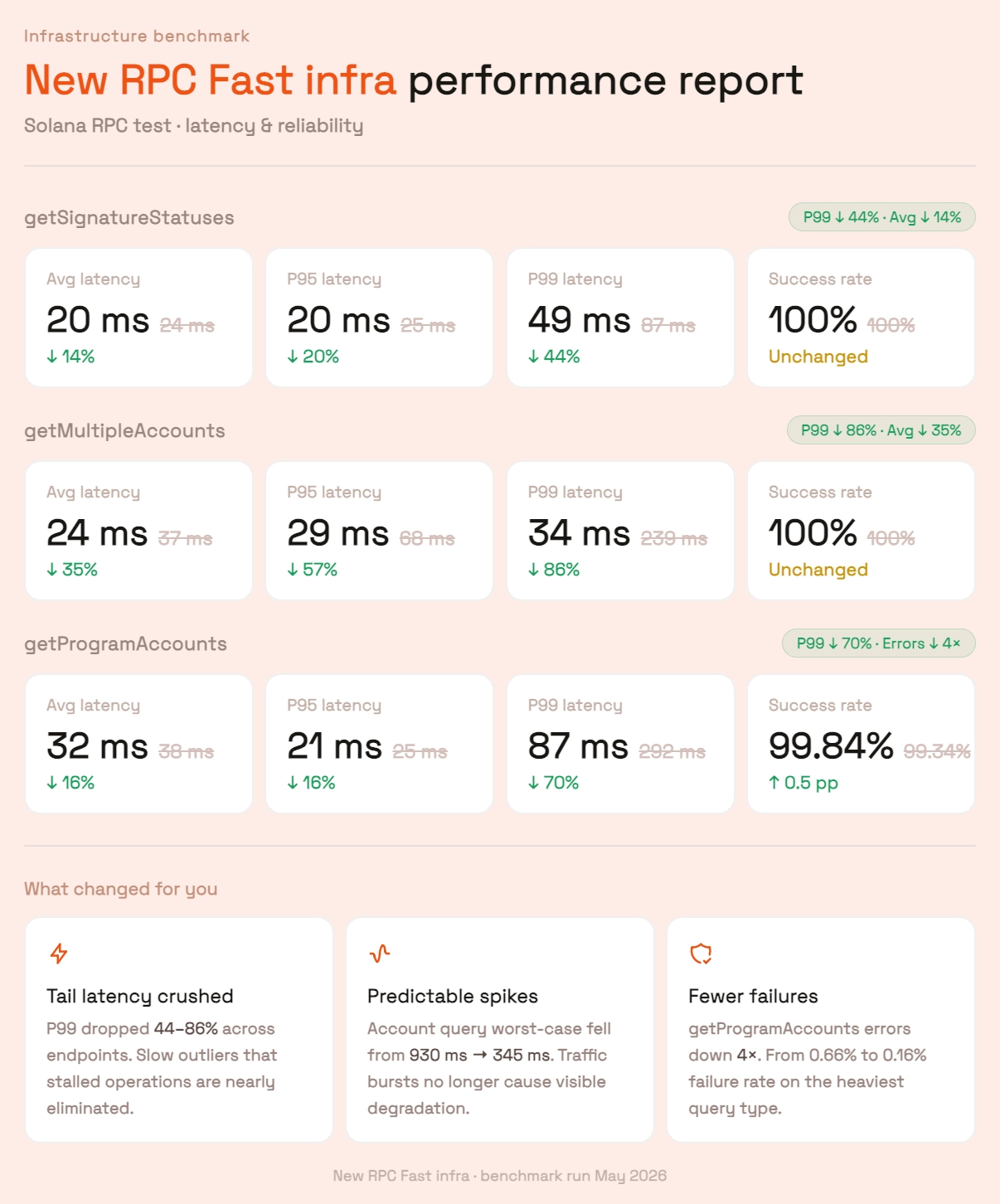
- Embeds Jito ShredStream, Yellowstone gRPC, and bloXroute Trader API into the node’s data plane;
- Implements smart routing so the node uses whichever feed delivers first and fan-outs transactions across relays;
- Monitors per-path latency and slot landing behavior, not only uptime.
Intended behavior
- Same-block with parent:
- Primary path: Jito bundles with child transactions sequenced after the observed or pre-signed parent
- Backup: fast single transactions via bloXroute and swQoS-enabled RPC for non-Jito slots or failures
- p99 latency:
- Under normal conditions, internal p99 from signal to “on-wire to leader” sits in the tens of ms
- End-to-end observed p99 (including inclusion confirmation) often stays well below generic seconds-level benchmarks, especially during non-maximal congestion
Running Architecture A but need Architecture B behavior? Time for a structured gap analysis.
Request an infra reviewExample scenario: Same-block backrun on Raydium
Scenario: a large swap on a Raydium pool moves the price sharply. You want to backrun it with a hedge on another venue in the same slot.
Architecture A
- Sees the parent through standard node + Yellowstone gRPC;
- Runs strategy on a cloud VM in a nearby region;
- Submits a Jito bundle only;
- On normal days, this often lands correctly;
- During high-volatility bursts, gossip delays and queuing inside Jito and the network push many trades into the next slot.
Architecture B (RPC Fast-style)
- Jito ShredStream delivers leader shreds hundreds of ms earlier than waiting for full gossip;
- Strategy runs on the same bare-metal machine, with low-single-digit ms compute and signing;
- It constructs a Jito bundle that includes the parent (if under control) and the backrun, or a child that relies on the new state;
- It submits:
- The bundle—to Jito Block Engine;
- A parallel transaction via bloXroute Trader API;
- A parallel path via a staked RPC with swQoS.
- If one relay path degrades, another still gives a chance for same-slot landing.
Choosing B: Same-block success rate on hot pools increases, especially when the network is busy. You still lose some races. But fewer of them are infra-related.
How to evaluate your current setup in 1–2 weeks
You do not need a full rewrite to understand whether you are closer to Architecture A or B. Follow this simple tactic to shed some light on the state of your current setup.

-
Collect baseline metrics. Start logging:
- signal_time
- submit_time per path
- inclusion_time and slot
For same-block strategies:
- parent_signature
- child_signature
- Are they in the same slot, and in the correct order?
-
Map your architecture
- Where are your bots running (cloud regions, DCs)?
- Which RPCs and relays do you use?
- Do you have any swQoS relationships?
- How many independent submit paths exist for critical trades?
-
Run controlled endpoint tests. Build a small harness that:
- Sends simple swaps with fixed fees and tips to public RPC, your current primary RPC, any low-latency / MEV endpoints you have access to (including RPC Fast — the free Start plan needs no card, so a baseline run costs nothing).
- Records slots-to-land, time from submit to inclusion, drop rate during a busy window.
-
Pick your target
- If your strategies are profitable with seconds-level inclusion and rare same-block hits, Architecture A with incremental tuning might be enough.
- If missing same-block opportunities visibly erodes P&L, you need an Architecture B-style design, whether you build it yourself or work with partners like RPC Fast and Dysnix.
Next step: Get a low-friction infra briefing
You do not need to commit to a full HFT rebuild to get value here. Bring your current metrics, architecture diagrams, and trading patterns to the RPC Fast infra briefing. And we bring:
- A reference checklist for Solana low-latency trading
- Architecture A/B templates
- A view on where RPC Fast’s managed infra and Dysnix’s DevOps work can or cannot help.
From there, you decide whether to keep tuning in-house, adopt a managed stack, or design a hybrid. The important part is that your infra finally matches the strategies you are already smart enough to build.
Schedule your free infra briefing for an architecture review
Drop a line.jpg)





